Pesquisadores de bioengenharia da UCLA criam adesivo autoalimentado que traduz os movimentos musculares da garganta da fala silenciosa em fala falada usando aprendizado de máquina
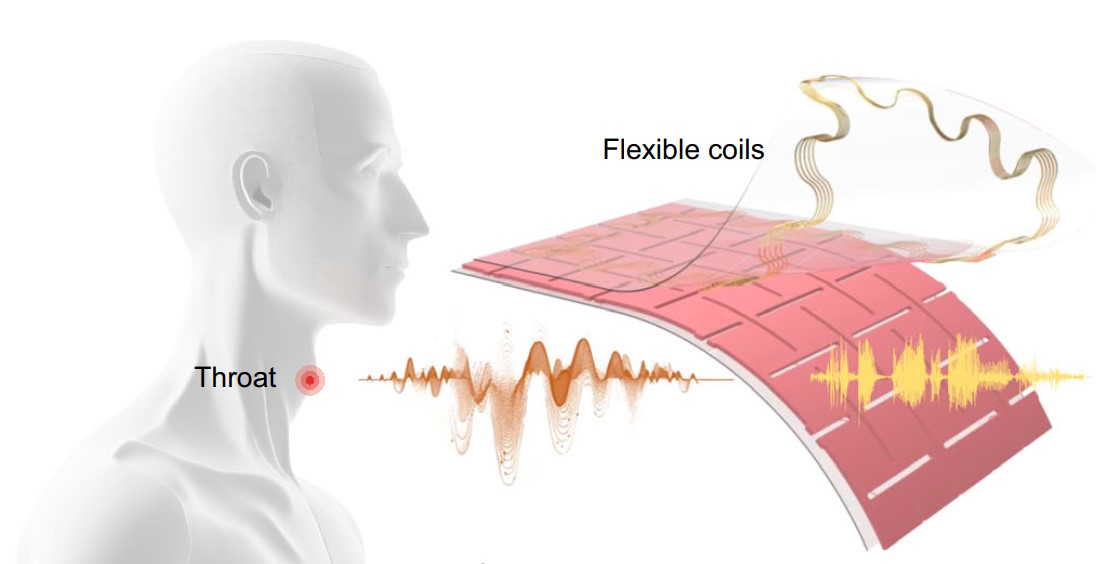
Um grupo de pesquisadores de bioengenharia da UCLA criou um adesivo flexível e autoalimentado que traduz os movimentos dos músculos da laringe na superfície do pescoço durante a fala silenciosa em fala falada usando aprendizado de máquina. Esse adesivo vestível permite que pessoas mudas ou que não conseguem falar adequadamente devido a lesões, doenças ou distúrbios das pregas vocais falem usando o sistema de adesivo de voz.
A voz humana é criada durante a expiração do ar pela garganta e modulada pelos diversos músculos da laringe presentes. Todos os músculos da laringe precisam se mover em coordenação para produzir a fala, e os movimentos na superfície do pescoço são um reflexo dos movimentos no interior da garganta.
Especificamente, a laringe é a mais importante, pois contém os músculos das cordas vocais que mudam de forma ao criar sons diferentes. A laringite e o uso excessivo das cordas vocais (gritar, cantar ou berrar) são motivos comuns pelos quais uma pessoa não consegue falar porque os principais músculos não se movem corretamente para gerar o som. Entretanto, mesmo quando as cordas vocais não funcionam adequadamente, outros músculos da laringe ainda se movem na tentativa de falar.
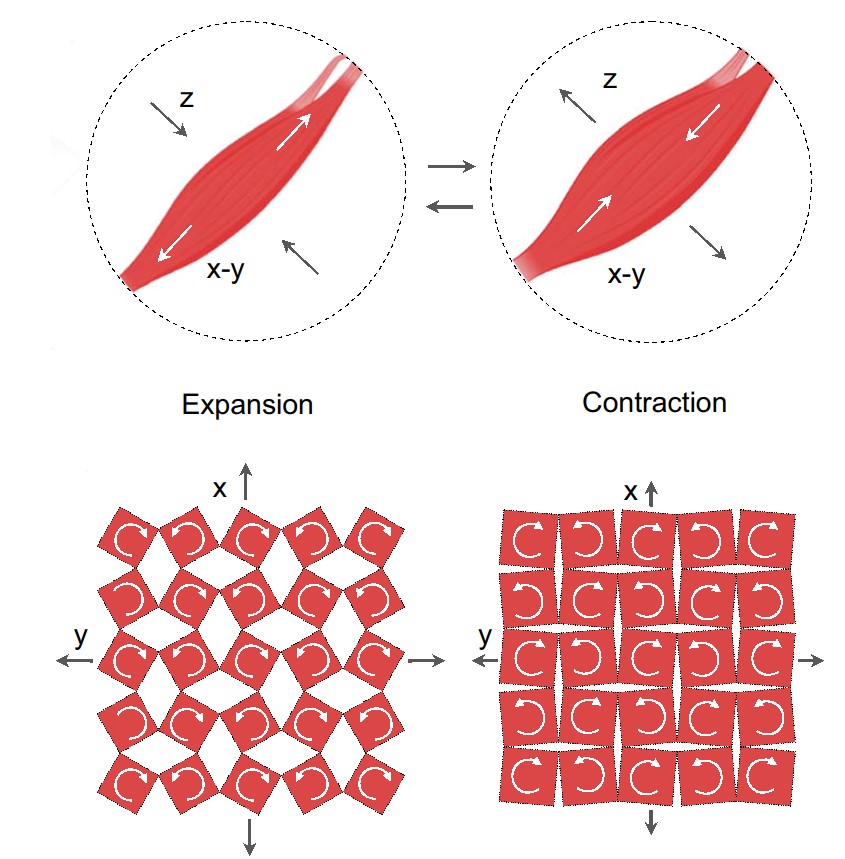
Os pesquisadores criaram um adesivo que pode detectar o movimento dos músculos da garganta. O adesivo tem camadas externas de polidimetilsiloxano (PDMS) que ensanduicham duas camadas de bobinas de cobre que servem como camadas de indução magnética (MI), separadas por uma única camada de PDMS e ímãs que servem como camada de acoplamento magneto-mecânico (MC). A camada MC tem muitas incisões para permitir que ela se expanda e se contraia mais facilmente quando os músculos da garganta se flexionam.
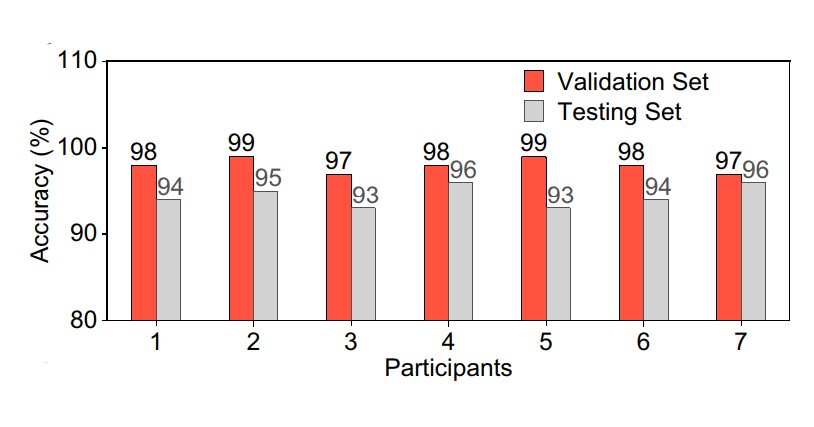
Quando uma pessoa tenta falar usando o adesivo de 7,2 gramas, os músculos se movem e o adesivo se flexiona, gerando um pequeno sinal elétrico que é captado pelo módulo sensor. O sinal é processado e, em seguida, passado para o módulo de aprendizado de máquina, que analisa o sinal e interpreta o que o locutor está tentando dizer a partir de um conjunto de cinco frases usadas para treinar o sistema. Em 40 ms, o computador fala a frase pretendida com uma precisão de 94,68%.
O sistema precisa ser treinado em uma gama muito maior de palavras e frases antes que a tecnologia de voz vestível possa vocalizar a fala comum, portanto, os leitores mudos podem achar útil um livro sobre código Morse ou linguagem de sinais enquanto aguardam o adesivo.