

Comunicações internas que vazaram revelam que a Nvidia coleta diariamente vídeos do YouTube que valem uma vida inteira para treinar o modelo de IA de vídeo, e Jensen está satisfeito com o progresso

A Nvidia está treinando seu Omniverse, carros autônomos e carros "humanos digitais" com base em dados extraídos de "80 anos de vídeos por dia" do YouTube e de outras fontes, revelou uma investigação da 404 Media.
Comunicações internas vazadas obtidas pelo 404 Media indicam que a Nvidia está usando esses dados para treinar seu modelo de mundo de vídeo de IA apelidado de Cosmos (não confundir com o serviço de aprendizagem profunda Cosmos existente da empresa)). O Cosmos está internamente programado para ser um modelo que alimentaria outras linhas da Nvidia, incluindo GeForce, arquitetura de GPU, DGX, estruturas de Deep Learning, Omniverse, Avatar, Project GR00T e veículos autônomos.
Os executivos da Nvidia apelidaram o Cosmos como um modelo de base de última geração"que encapsula a simulação de transporte de luz, física e inteligência em um só lugar para desbloquear vários aplicativos downstream essenciais para a Nvidia"
a 404 Media acessou mensagens internas do Slack de funcionários que revelaram como a equipe usou o programa de linha de comando yt-dlp para baixar vídeos do YouTube usando de 20 a 30 máquinas virtuais da AWS que atualizam os endereços IP para evitar serem bloqueados pelo YouTube. O site de compartilhamento de vídeos foi a principal fonte para a extração de vídeos, e os funcionários também analisaram outras fontes, como Netflix e Discovery Channel.
As comunicações do Slack mostram os funcionários discutindo as ramificações legais da extração de conteúdo protegido por direitos autorais para treinar a IA, o que foi descartado pelos gerentes de projeto como uma decisão executiva, e isso é algo com que eles não precisam se preocupar.
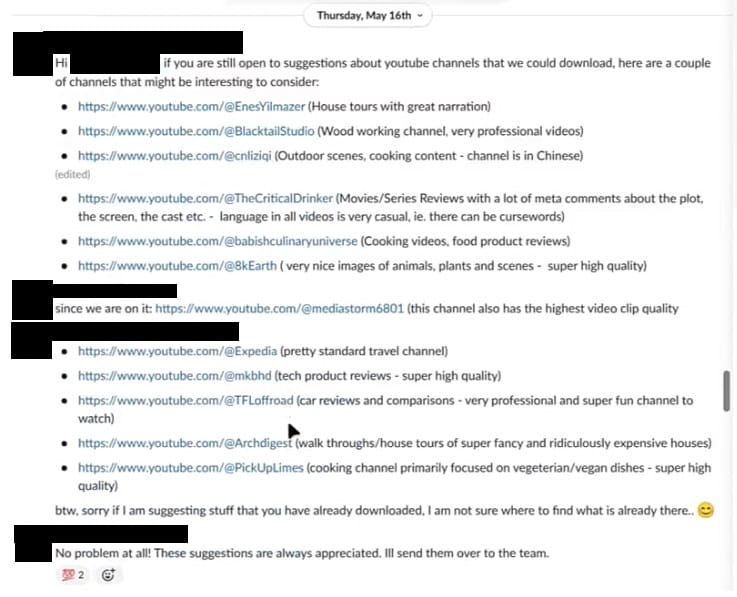
Os canais populares do YouTube que os funcionários da Nvidia selecionaram incluem MKBHD, PickUpLimes, Architectural Digest, Expedia, Mediastorm6801, 8kEarth e The CriticalDrinker, entre outros.
Quando contatadas pela 404 Media, tanto o YouTube quanto a Netflix disseram que a extração de conteúdo em suas plataformas para treinar modelos de IA é uma clara violação de seus termos de serviço.
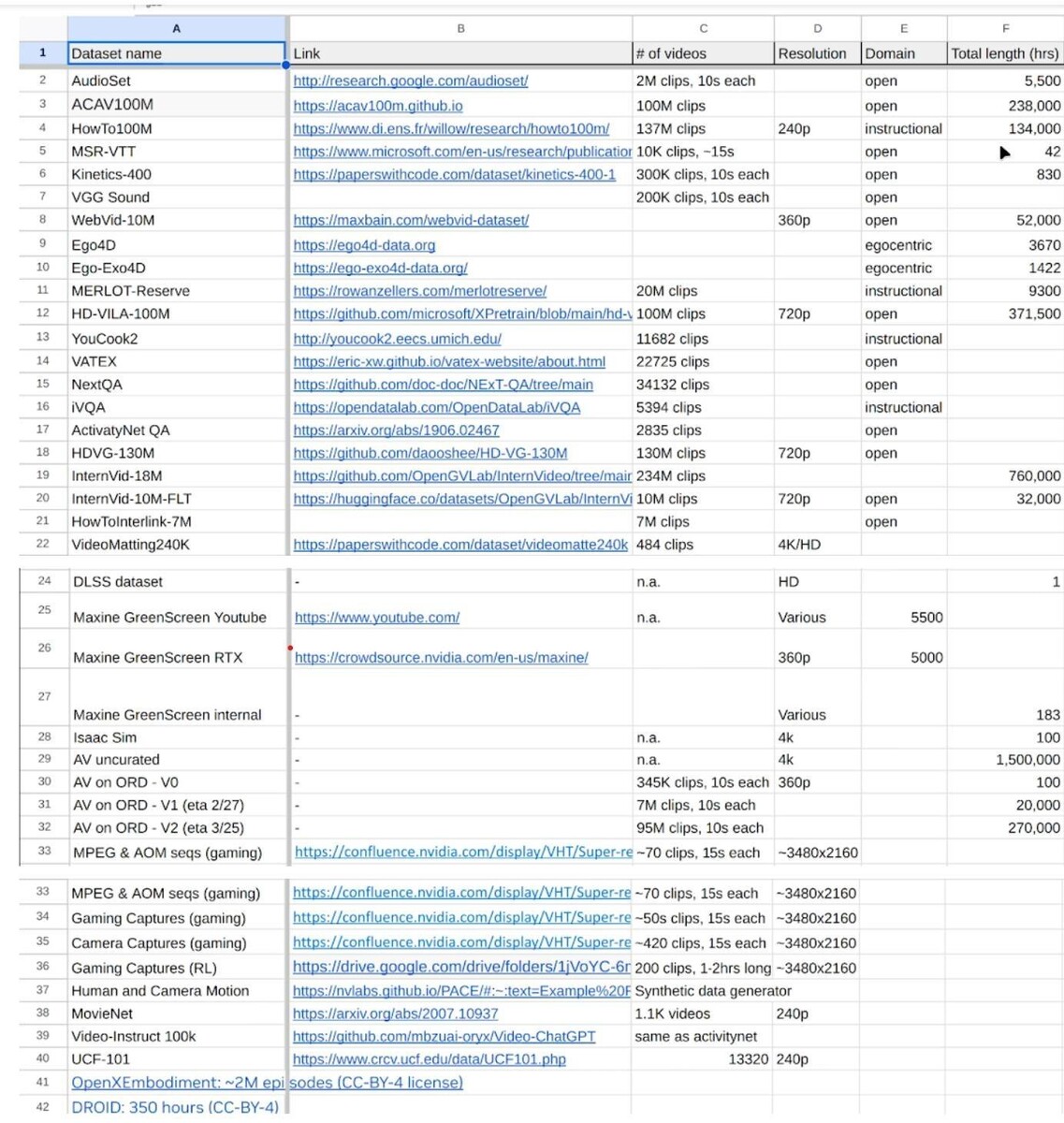
O uso de dados protegidos por direitos autorais para treinar modelos de IA ainda é uma área cinzenta do ponto de vista jurídico. Conjuntos de dados públicos, como InternVid-10M, HD-VG-130Me outros baseados em milhões de vídeos do YouTube, mas eles se destinam apenas à pesquisa acadêmica e não a fins comerciais. Embora a Nvidia tenha pesquisadores acadêmicos, o resultado acabará chegando a um produto comercial.
Existem poucas legislações nesse sentido, que determinam padrões de transparência e exigem que as empresas que trabalham com modelos fundamentais de IA trabalhem com a FTC e o Copyright Office. Mas as empresas não necessariamente divulgam seus conjuntos de dados de origem, o que torna a auditoria muito mais difícil.
Como as principais empresas de IA continuam a colocar as mãos em todos os dados públicos disponíveis para treinar modelos mais eficazes, as mudanças legislativas são uma necessidade urgente para garantir a segurança do consumidor e proteger a propriedade intelectual do criador.
No ano passado, o The New York Times processou a OpenAI e a Microsoft por uso não autorizado dos artigos protegidos por direitos autorais da publicação para treinar modelos de IA. Em maio, os artistas visuais entraram com uma ação judicial contra a Stability AI, Midjourney, DeviantArt e Runway AI por usarem cópias de seus trabalhos para treinar modelos de IA sem permissão.
O YouTube está se tornando uma mina de ouro de dados para as empresas de IA. Recentemente, a Wired informou que pesos pesados, incluindo Apple, Nvidia, Anthropic e Salesforce, extraíram legendas de 173.536 vídeos do YouTube de mais de 48.000 canais para treinar sua IA.
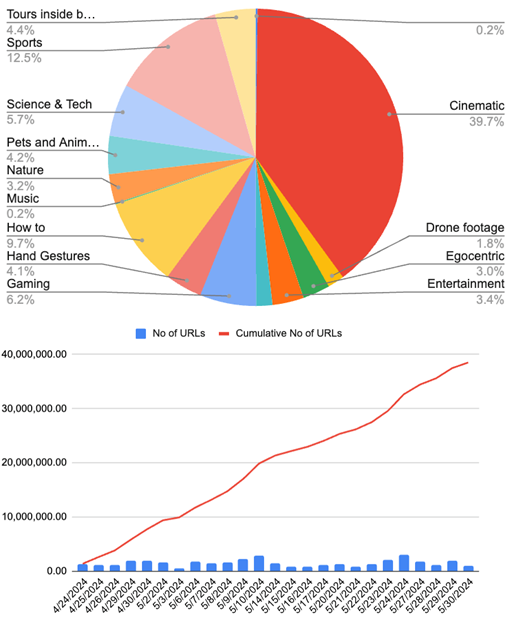
Até o final de maio, a equipe da Nvidia anunciou internamente que havia compilado 38,5 milhões de URLs de vídeos, sendo a maioria deles de conteúdo cinematográfico. Os engenheiros também adicionaram conjuntos de dados, como Ego-Exo4D, Ego4D, HOI4De dados de jogos do site GeForce Now.
Enquanto o Ego-Exo4D e o Ego4D podem ser licenciados para uso acadêmico e comercial, o HOI4D é distribuído sob uma licença CC BY-NC que proíbe especificamente o uso comercial.
Atualmente, a equipe está treinando um modelo de 1B com 16 nós cada, com planos de aumentar para 10B.
A Nvidia disse à 404 Media por e-mail que"nossos modelos e nossos esforços de pesquisa estão em total conformidade com a letra e o espírito da lei de direitos autorais"
Enquanto isso, o CEO da Nvidia, Jensen Huang, parece estar feliz com o progresso que sua equipe está fazendo.
Ele teria exclamado: "Ótima atualização. Muitas empresas precisam criar FMs de vídeo [modelos fundamentais]. Podemos oferecer um pipeline totalmente acelerado"
SCOOP from @samleecole: Leaked Slacks and documents show the incredible scale of NVidia's AI scraping: 80 years — "a human lifetime" of videos every day. Had approval from highest levels of company despite staff legal/ethical concerns:https://t.co/DydXOyffUQ
— Jason Koebler (@jason_koebler) August 5, 2024
Fonte(s)
404 Mídia (requer registro)
















