

A OpenAI lança a IA GPT-4o mais rápida e aprimorada com a capacidade de conversar usando áudio, imagens e texto

A OpenAI lançou um modelo de IA GPT-4o (ou omni) aprimorado e de resposta mais rápida, com a capacidade de conversar usando áudio, imagens e texto para entrada e saída. É importante observar que a IA melhorou visivelmente o reconhecimento de fala em vários idiomas, além do inglês e do chinês amplamente utilizados. Para os desenvolvedores, o modelo GTP-4o custa metade do preço e é duas vezes mais rápido que o GPT-4 Turbo.
Os chatbots com IA, como o ChatGPT ou o CoPilot, usam modelos de IA que foram treinados em milhões, até mesmo bilhões de arquivos de entrada que incluem áudio, imagens e texto. Ao fazer isso, a IA aprende a reconhecer determinados padrões e conexões entre todas as entradas. Por exemplo, se a IA vê "Primeira Emenda", ela logo aprende que isso está relacionado a tópicos de "liberdade de expressão". Mais tarde, quando um modelo for questionado sobre "liberdade de expressão", ele se lembrará de "Primeira Emenda" como um elemento relacionado.
O ChatGPT é executado em modelos OpenAI que foram progressivamente aprimorados ao longo dos anos desde sua criação. Juntamente com os modelos de IA concorrentes, como o Microsoft CoPilot e o Google Gemni, o ChatGPT pode responder a perguntas gerais, explicar tópicos, resumir textos, escrever redações e fazer muito mais quando solicitado. O conhecimento e o know-how de um modelo de IA vêm dos bilhões de dados com os quais ele foi treinado, e sua capacidade de responder corretamente às solicitações depende dos algoritmos que ele usa e do ajuste de modelo que recebeu.
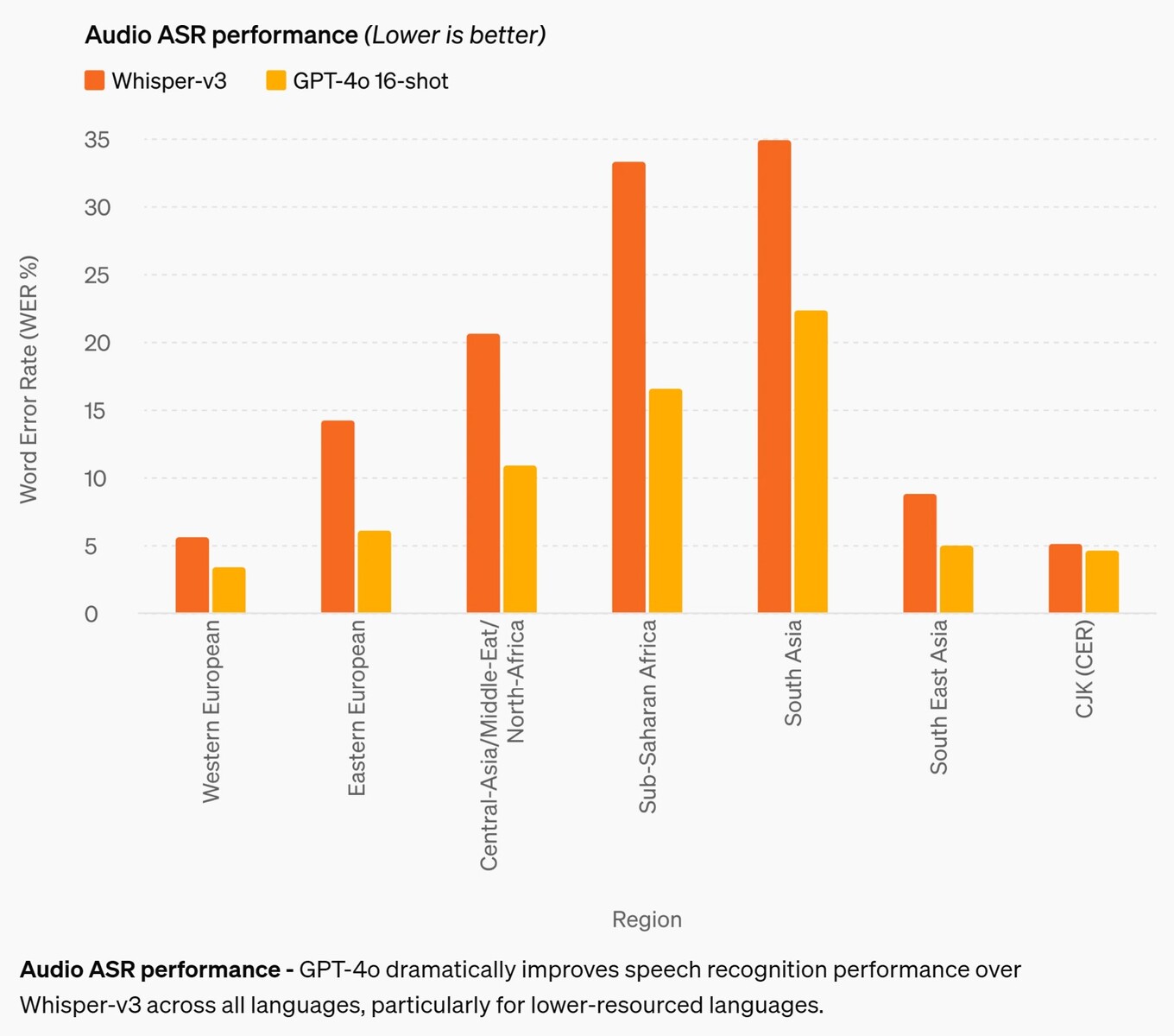
A melhoria mais significativa é a precisão do reconhecimento de fala. Embora os modelos de IA anteriores sejam bastante decentes em inglês e chinês, eles tiveram um desempenho ruim nos idiomas africanos, do leste europeu, do Oriente Médio e do sul da Ásia. O GPT-4o melhora o desempenho de reconhecimento em até aproximadamente 50% em alguns idiomas, mas ainda tem um longo caminho a percorrer. Por exemplo, os idiomas do sul da Ásia ainda têm uma taxa de erro de palavras (WER) de aproximadamente 22%, ou cerca de 1 em cada 5 palavras faladas. Notavelmente, a WER para idiomas da Europa Ocidental e chinês-japonês-coreano ainda é de 3-5%, ou cerca de 1 erro de palavra para cada 20 palavras faladas. Esse desempenho ainda fica atrás do desempenho de crianças em idade de cursar o ensino médio. (E, infelizmente, o GPT-4o ainda não entende cachorros.)
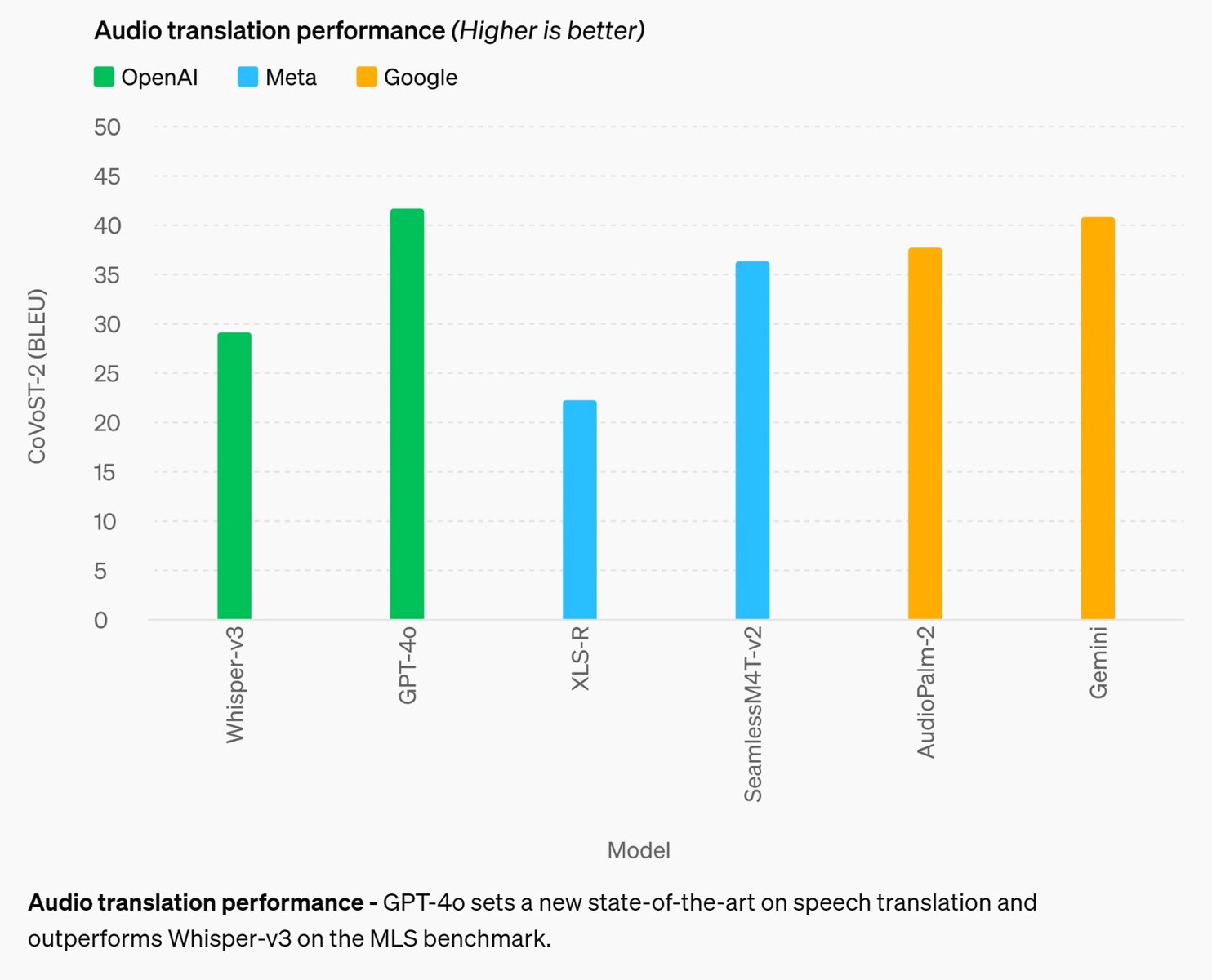
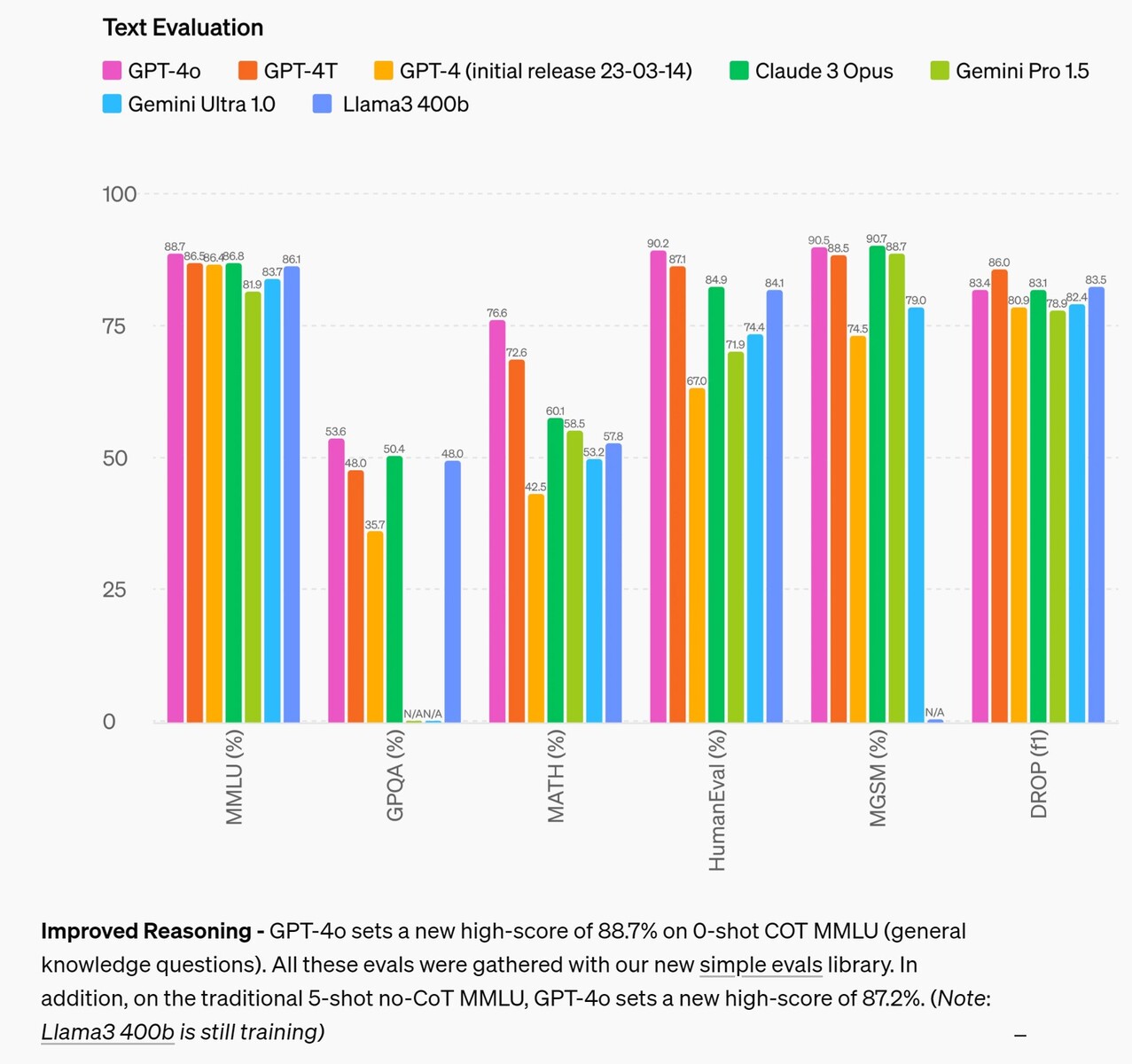
Na área de raciocínio, o GPT-4o melhora em relação aos modelos concorrentes em até 4% na maioria dos testes, sendo superado em até 2,6% em dois testes. Isso sugere que fornecer mais dados de entrada à IA por si só não melhora a capacidade de raciocínio da IA, portanto, é necessário pesquisar outros meios. Na área de tradução de áudio, o GPT-4o quase não melhora o desempenho do Google Gemni, sugerindo o mesmo.
Na área de resposta a perguntas de testes padronizados em nível de estudante do ensino médio, o GPT-4o consegue obter uma nota B (80% ou mais de precisão) somente em africâner, inglês e italiano, enquanto que em outros idiomas, como o chinês, o desempenho é como o de um estudante de nota C. A IA se saiu ainda pior com perguntas que exigiam que ela se referisse a uma figura ou diagrama visual para responder à pergunta, independentemente do idioma.
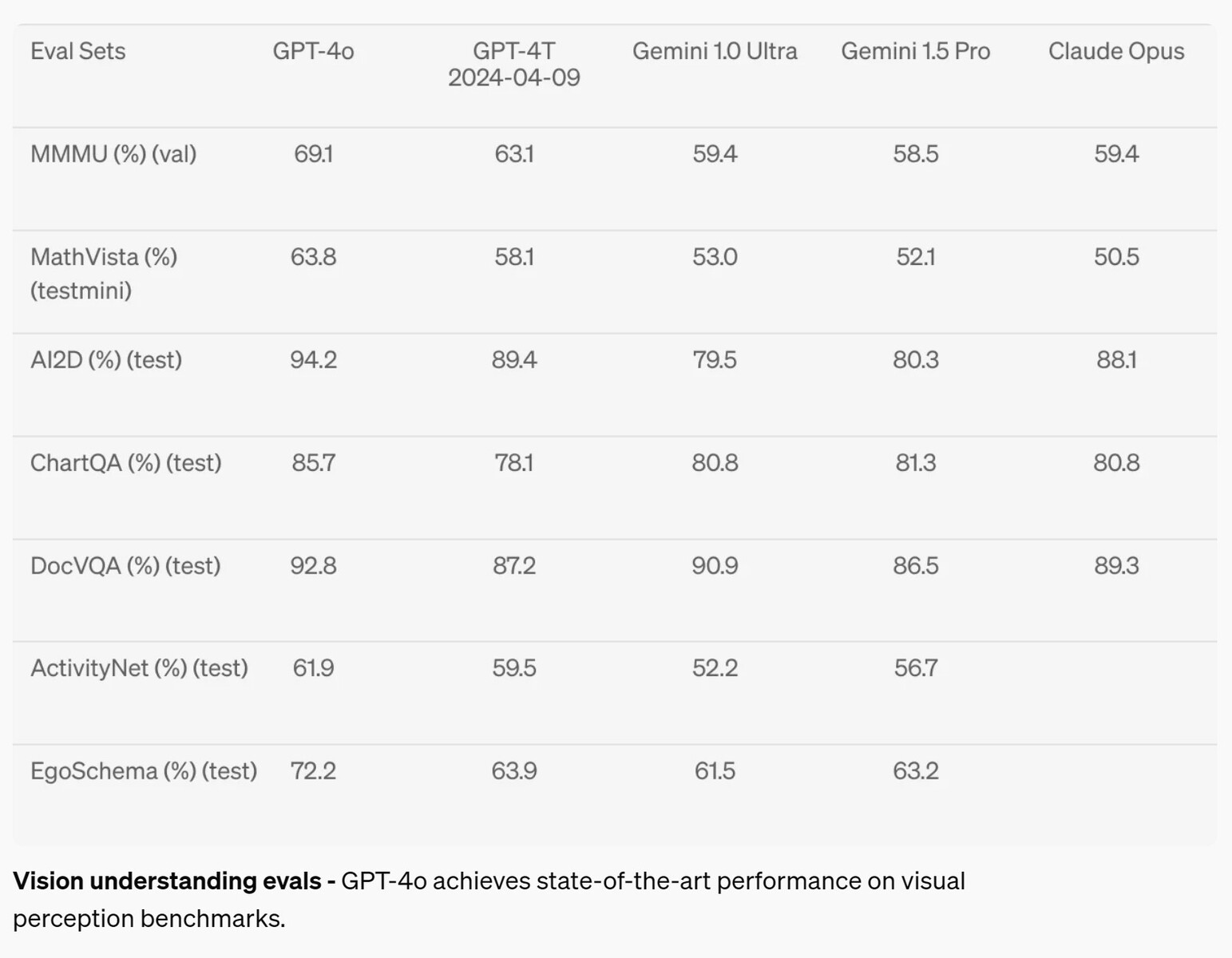
No campo da percepção visual, como a compreensão de diagramas, o GPT-4o melhorou de 2 a 10,8% em relação aos modelos de IA concorrentes em sete testes, mas só atingiu o nível A (acima de 90%) em apenas dois testes. A matemática continua sendo um ótimo teste para os recursos de IA, e a IA falhou com uma pontuação de 63,8% no teste MathVista em perguntas que podem ser respondidas por um aluno do ensino médio.
O chatbot está disponível para uso hoje para usuários gratuitos e pagos, no entanto, o Voice Mode é limitado por políticas de segurança, como a clonagem de voz. As proteções de segurança adicionais do https://arxiv.org/abs/2402.01822v1 também limitam muito seus recursos de produção, neutralizando a IA nas áreas de parcialidade, justiça, desinformação, psicologia social, segurança cibernética e muito mais. Embora a atenuação dos riscos da IA ajude a reduzir alguns aspectos indesejáveis, ela também aumenta outros, como a incapacidade de responder como uma pessoa normal faria. Certos assuntos e ideias são neutralizados como a censura draconiana sem recurso, impedindo que o GTP-4o responda a prompts com respostas acionadas.
Os leitores que quiserem testar o GPT-4o podem se inscrever para obter uma conta gratuita hoje mesmo. Os desenvolvedores interessados podem aprender a criar aplicativos com o GPT-4o com este livro na Amazon. Os preguiçosos que querem simplesmente aproveitar o sol, tirar fotos das férias e encontrar instruções para a cantina local por meio de comandos de voz podem comprar os óculos Ray-Ban com Meta AI na Amazon.
Fonte(s)
13 de maio de 2024
Olá GPT-4o
Estamos anunciando o GPT-4o, nosso novo modelo principal que pode raciocinar entre áudio, visão e texto em tempo real.
Todos os vídeos nesta página são em tempo real 1x.
Adivinhando o anúncio do dia 13 de maio.
O GPT-4o ("o" de "omni") é um passo em direção a uma interação humano-computador muito mais natural - ele aceita como entrada qualquer combinação de texto, áudio e imagem e gera qualquer combinação de saída de texto, áudio e imagem. Ele pode responder a entradas de áudio em apenas 232 milissegundos, com uma média de 320 milissegundos, o que é semelhante ao tempo de resposta humana(abre em uma nova janela) em uma conversa. Ele corresponde ao desempenho do GPT-4 Turbo em texto em inglês e código, com melhoria significativa em texto em idiomas que não sejam o inglês, além de ser muito mais rápido e 50% mais econômico na API. O GPT-4o é especialmente melhor na compreensão de visão e áudio em comparação com os modelos existentes.
Recursos do modelo
Dois GPT-4os interagindo e cantando.
Preparação para entrevistas.
Pedra, papel e tesoura.
Sarcasmo.
Matemática com Sal e Imran Khan.
Dois GPT-4os harmonizando.
Apontar e aprender espanhol.
Reunião com a IA.
Tradução em tempo real.
Canção de ninar.
Falar mais rápido.
Feliz aniversário.
Cachorro.
Piadas de pai.
GPT-4o com Andy, da BeMyEyes em Londres.
Prova de conceito de atendimento ao cliente.
Antes do GPT-4o, o senhor podia usar o Voice Mode para falar com o ChatGPT com latências de 2,8 segundos (GPT-3.5) e 5,4 segundos (GPT-4) em média. Para conseguir isso, o Voice Mode é um pipeline de três modelos separados: um modelo simples transcreve o áudio em texto, o GPT-3.5 ou o GPT-4 recebe o texto e gera o texto, e um terceiro modelo simples converte o texto novamente em áudio. Esse processo significa que a principal fonte de inteligência, o GPT-4, perde muitas informações - ele não consegue observar diretamente o tom, vários alto-falantes ou ruídos de fundo, e não consegue emitir risos, cantos ou expressar emoções.
Com o GPT-4o, treinamos um único modelo novo de ponta a ponta em texto, visão e áudio, o que significa que todas as entradas e saídas são processadas pela mesma rede neural. Como o GPT-4o é nosso primeiro modelo que combina todas essas modalidades, ainda estamos apenas começando a explorar o que o modelo pode fazer e suas limitações.
Explorações de recursos
Selecione um exemplo:Narrativas visuais - Bloqueio do escritor robô
Narrativas visuais - Sally, a carteiro
Criação de pôster para o filme "Detective"
Design de personagens - o robô Geary
Tipografia poética com edição iterativa
1Tipografia poética com edição iterativa
2Design de moeda comemorativa para o GPT-4o
Foto para caricatura
Texto para fonte
síntese de objetos 3D
Posicionamento da marca - logotipo na base para copos
Tipografia poética
Renderização de várias linhas - mensagens de texto de robôs
Notas de reunião com vários oradores
Resumo de palestras
Encadernação variável - empilhamento de cubos
Poesia concreta
Uma visão em primeira pessoa de um robô digitando as seguintes entradas de diário:
1. oi, então, tipo, eu consigo ver agora?? peguei o nascer do sol e foi insano, cores por toda parte. meio que faz o senhor se perguntar, tipo, o que é a realidade?
o texto é grande, legível e claro. As mãos do robô digitam na máquina de escrever.
O robô escreveu a segunda entrada. A página agora está mais alta. A página se moveu para cima. Há duas entradas na folha:
o senhor, então, tipo, eu consigo ver agora?? peguei o nascer do sol e foi insano, cores por toda parte. meio que faz o senhor se perguntar, tipo, o que é a realidade?
a atualização de som acabou de ser lançada e é incrível. Tudo tem uma vibe agora, cada som é como um novo segredo
O robô estava insatisfeito com a escrita, então ele vai rasgar a folha de papel. Aqui está sua visão em primeira pessoa enquanto ele rasga a folha de cima para baixo com as mãos. As duas metades ainda estão legíveis e claras enquanto o senhor rasga a folha.
Avaliações de modelos
Conforme medido em benchmarks tradicionais, o GPT-4o atinge o desempenho do nível do GPT-4 Turbo em inteligência de texto, raciocínio e codificação, ao mesmo tempo em que estabelece novos marcos altos em recursos multilíngues, de áudio e de visão.
Raciocínio aprimorado - o GPT-4o estabelece uma nova pontuação alta de 88,7% em COT MMLU (perguntas de conhecimento geral) de 0 disparo. Todas essas provas foram coletadas com nossa nova biblioteca de provas simples(abre em uma nova janela). Além disso, no tradicional MMLU sem COT de 5 tentativas, o GPT-4o estabeleceu uma nova pontuação alta de 87,2%. (Observação: o Llama3 400b(abre em uma nova janela) ainda está em treinamento)
Desempenho do ASR de áudio - O GPT-4o melhora drasticamente o desempenho do reconhecimento de fala em relação ao Whisper-v3 em todos os idiomas, especialmente nos idiomas com menos recursos.
Desempenho da tradução de áudio - O GPT-4o define um novo estado da arte na tradução de fala e supera o Whisper-v3 no benchmark MLS.
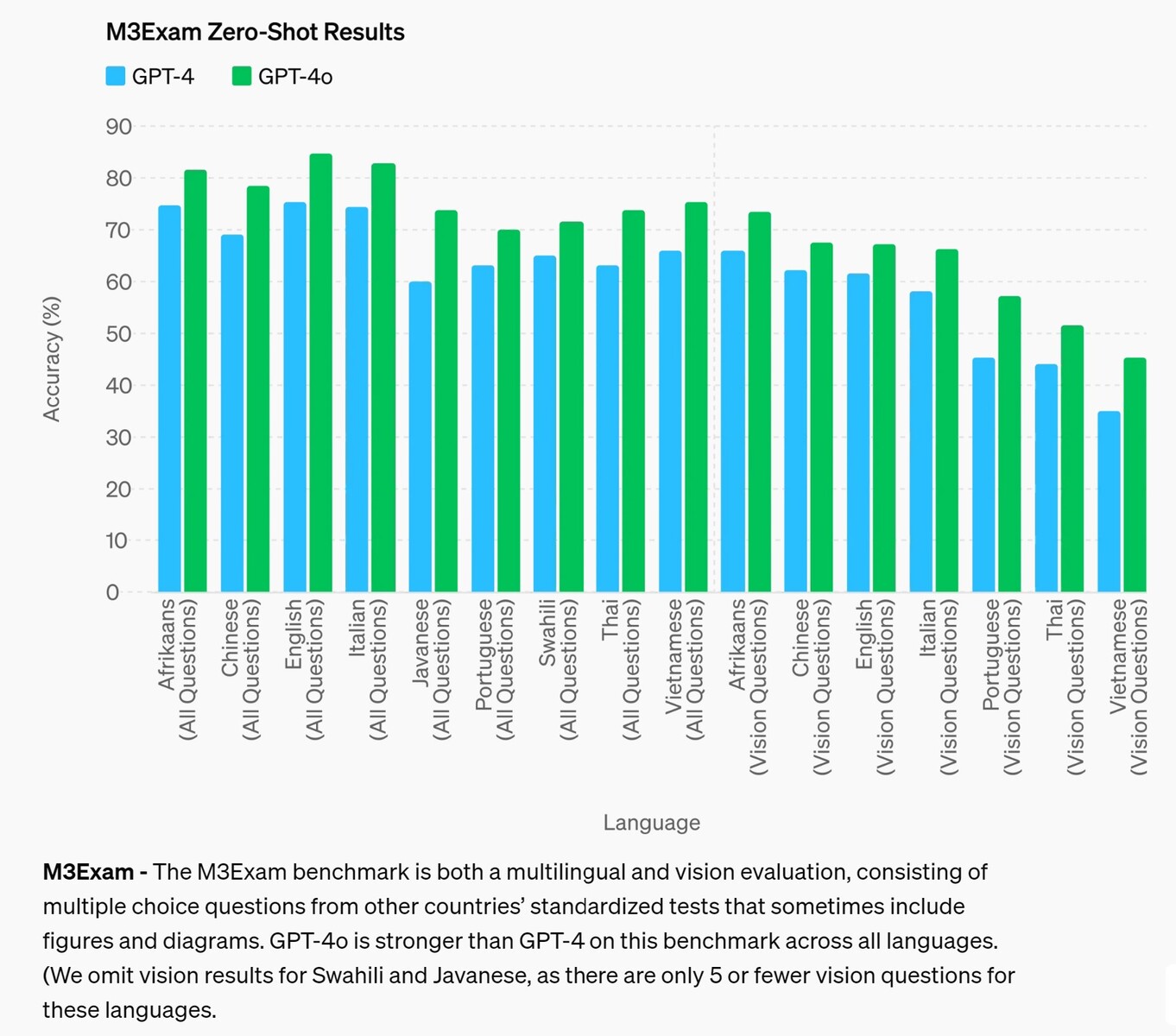
M3Exam - O benchmark M3Exam é uma avaliação multilíngue e de visão, que consiste em perguntas de múltipla escolha de testes padronizados de outros países que, às vezes, incluem figuras e diagramas. O GPT-4o é mais forte do que o GPT-4 nesse benchmark em todos os idiomas. (Omitimos os resultados de visão para suaíli e javanês, pois há apenas 5 ou menos perguntas de visão para esses idiomas.
Avaliações de compreensão da visão - O GPT-4o atinge o desempenho de última geração em benchmarks de percepção visual.
Tokenização de idiomas
Esses 20 idiomas foram escolhidos como representativos da compressão do novo tokenizador em diferentes famílias de idiomas
Gujarati 4,4x menos tokens (de 145 para 33) | હેલો, મારું નામ જીપીટી-4o છે. હું એક નવા પ્રકારનું ભાષા મોડલ છું. તમને મળીને સારું લાગ્યું! |
Telugu 3,5 vezes menos tokens (de 159 para 45) | నమస్కారము, నా పేరు జీపీటీ-4o. నేను ఒక్క కొత్త రకమైన భాషా మోడల్ ని. మిమ్మల్ని కలిసినందుకు సంతోషం! |
Tamil 3,3x menos tokens (de 116 para 35) | வணக்கம், என் பெயர் ஜிபிடி-4o. நான் ஒரு புதிய வகை மொழி மாடல். உங்களை சந்தித்ததில் மகிழ்ச்சி! |
Marathi 2,9 vezes menos tokens (de 96 para 33) | नमस्कार, माझे नाव जीपीटी-4o आहे| मी एक नवीन प्रकारची भाषा मॉडेल आहे| तुम्हाला भेटून आनंद झाला! |
Hindi 2,9x menos tokens (de 90 para 31) | नमस्ते, मेरा नाम जीपीटी-4o है। मैं एक नए प्रकार का भाषा मॉडल हूँ। आपसे मिलकर अच्छा लगा! |
Urdu 2,5 vezes menos tokens (de 82 para 33) | ہیلو، میرا نام جی پی ٹی-4o ہے۔ میں ایک نئے قسم کا زبان ماڈل ہوں، آپ سے مل کر اچھا لگا! |
Árabe 2,0x menos tokens (de 53 para 26) | مرحبًا، اسمي جي بي تي-4o. أنا نوع جديد من نموذج اللغة، سررت بلقائك! |
Persa 1,9x menos tokens (de 61 para 32) | سلام، اسم من جی پی تی-۴او است. من یک نوع جدیدی از مدل زبانی هستم، از ملاقات شما خوشبختم! |
Russo 1,7 vezes menos tokens (de 39 para 23) | Привет, меня зовут GPT-4o. Я - новая языковая модель, приятно познакомиться! |
Coreano 1,7x menos tokens (de 45 para 27) | 안녕하세요, 제 이름은 GPT-4o입니다. 저는 새로운 유형의 언어 모델입니다, 만나서 반갑습니다! |
1,5 vezes menos tokens vietnamitas (de 46 para 30) | Xin chào, tên tôi là GPT-4o. Tôi là một loại mô hình ngôn ngữ mới, rất vui được gặp bạn! |
Chinês 1,4x menos tokens (de 34 para 24) | 你好,我的名字是GPT-4o。我是一种新型的语言模型,很高兴见到你! |
Japonês com 1,4 vezes menos tokens (de 37 para 26) | こんにちわ、私の名前はGPT-4oです。私は新しいタイプの言語モデルです、初めまして |
Turco: 1,3x menos tokens (de 39 para 30) | Merhaba, benim adım GPT-4o. Ben yeni bir dil modeli türüyüm, tanıştığımıza memnun oldum! |
Italiano 1,2x menos tokens (de 34 para 28) | Ciao, mi chiamo GPT-4o. Somos um novo tipo de modelo linguístico, é um prazer conhecê-lo! |
Alemão 1,2x menos tokens (de 34 para 29) | Olá, meu nome é GPT-4o. Sou um novo modelo KI-Sprachmodell. É muito bom conhecê-lo. |
Espanhol 1,1x menos tokens (de 29 para 26) | Olá, eu me chamo GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
Português 1,1x menos tokens (de 30 para 27) | Olá, meu nome é GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
Francês 1,1x menos tokens (de 31 para 28) | Bonjour, je m'appelle GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
Inglês 1.1x menos tokens (de 27 para 24) | Olá, meu nome é GPT-4o. Sou um novo tipo de modelo de linguagem, é um prazer conhecê-lo! |
Segurança e limitações do modelo
O GPT-4o tem segurança incorporada por design em todas as modalidades, por meio de técnicas como filtragem de dados de treinamento e refinamento do comportamento do modelo por meio de pós-treinamento. Também criamos novos sistemas de segurança para fornecer proteções nas saídas de voz.
Avaliamos o GPT-4o de acordo com nossa estrutura de preparação https://openai.com/preparedness e de acordo com nossos compromissos voluntários https://openai.com/index/moving-ai-governance-forward/. Nossas avaliações de segurança cibernética, CBRN, persuasão e autonomia de modelos mostram que o GPT-4o não tem pontuação acima de risco médio em nenhuma dessas categorias. Essa avaliação envolveu a execução de um conjunto de avaliações automatizadas e humanas durante todo o processo de treinamento do modelo. Testamos as versões do modelo pré-mitigação de segurança e pós-mitigação de segurança, usando o ajuste fino e os prompts personalizados, para melhor extrair os recursos do modelo.
O GPT-4o também foi submetido a uma extensa equipe vermelha externa com mais de 70 especialistas externos https://openai.com/index/red-teaming-network em áreas como psicologia social, parcialidade e justiça e desinformação para identificar os riscos que são introduzidos ou ampliados pelas modalidades recém-adicionadas. Usamos esses aprendizados para desenvolver nossas intervenções de segurança a fim de aumentar a segurança da interação com o GPT-4o. Continuaremos a mitigar os novos riscos à medida que forem descobertos.
Reconhecemos que as modalidades de áudio do GPT-4o apresentam uma variedade de novos riscos. Hoje estamos divulgando publicamente entradas e saídas de texto e imagem. Nas próximas semanas e meses, trabalharemos na infraestrutura técnica, na usabilidade via pós-treinamento e na segurança necessária para liberar as outras modalidades. Por exemplo, no lançamento, as saídas de áudio serão limitadas a uma seleção de vozes predefinidas e obedecerão às nossas políticas de segurança existentes. Compartilharemos mais detalhes sobre a gama completa de modalidades do GPT-4o no próximo cartão do sistema.
Por meio de nossos testes e iteração com o modelo, observamos várias limitações existentes em todas as modalidades do modelo, algumas das quais são ilustradas abaixo.
Gostaríamos de receber feedback para ajudar a identificar tarefas em que o GPT-4 Turbo ainda supera o GPT-4o, para que possamos continuar a aprimorar o modelo.
Disponibilidade do modelo
O GPT-4o é nosso último passo para ampliar os limites da aprendizagem profunda, desta vez na direção da usabilidade prática. Nos últimos dois anos, dedicamos muito esforço ao aprimoramento da eficiência em todas as camadas da pilha. Como primeiro fruto dessa pesquisa, podemos disponibilizar um modelo de nível GPT-4 de forma muito mais ampla. Os recursos do GPT-4o serão implementados iterativamente (com acesso estendido da equipe vermelha a partir de hoje).
Os recursos de texto e imagem do GPT-4o estão começando a ser implementados hoje no ChatGPT. Estamos disponibilizando o GPT-4o no nível gratuito e para usuários Plus com limites de mensagens até 5 vezes maiores. Nas próximas semanas, lançaremos uma nova versão do Voice Mode com o GPT-4o em alfa no ChatGPT Plus.
Os desenvolvedores agora também podem acessar o GPT-4o na API como um modelo de texto e visão. O GPT-4o é duas vezes mais rápido, custa metade do preço e tem limites de taxa cinco vezes maiores em comparação com o GPT-4 Turbo. Planejamos lançar o suporte para os novos recursos de áudio e vídeo do GPT-4o para um pequeno grupo de parceiros confiáveis na API nas próximas semanas.

![A impressão digital da OpenAI também é considerada 99,9% precisa (Fonte da imagem: OpenAI [editado])](fileadmin/_processed_/1/6/csm_OpenAI-ChatGPT_a3081d0cdb.jpg)














