

A Meta apresenta o maior, mais inteligente e livre de royalties Llama 3.1 405B AI

A Meta revelou seu Llama 3.1 405B AI para uso livre de royalties. O modelo de linguagem grande (LLM) de 750 GB e 405 bilhões de parâmetros é um dos maiores já lançados, permitindo que ele tenha um desempenho competitivo com sua janela de entrada de token expandida de 128K em relação a carros-chefe de IA como Anthropic Claude 3.5 Sonnet e OpenAI GPT-4o. Diferentemente dos concorrentes pagos e de código fechado, os leitores podem personalizar e executar o LLM gratuito em seus próprios computadores equipados com placas gráficas (GPUs) Nvidia extremamente potentes.
Criação e energia
O Meta aproveitou até 16.384 GPUs 700W TDP GPUs H100 em sua plataforma de servidor Meta Grand Teton AI para produzir os 3,8 x 10^25 FLOPs necessários para criar um modelo de 405 bilhões de parâmetros em 16,55 trilhões de tokens (1.000 tokens são cerca de 750 palavras). As falhas relacionadas à GPU resultaram em 57,3% do tempo de inatividade durante o pré-treinamento, com 30,1% devido a GPUs defeituosas.
Mais de 54 dias foram gastos no pré-treinamento da IA em documentos, com um total de 39,3 milhões de horas de GPU usadas para treinar o Llama 3.1 405B. Uma estimativa rápida coloca o consumo de eletricidade durante o treinamento em mais de 11 GWh, com 11.390 toneladas de gases de efeito estufa equivalentes a CO2 liberados.
Segurança e desempenho
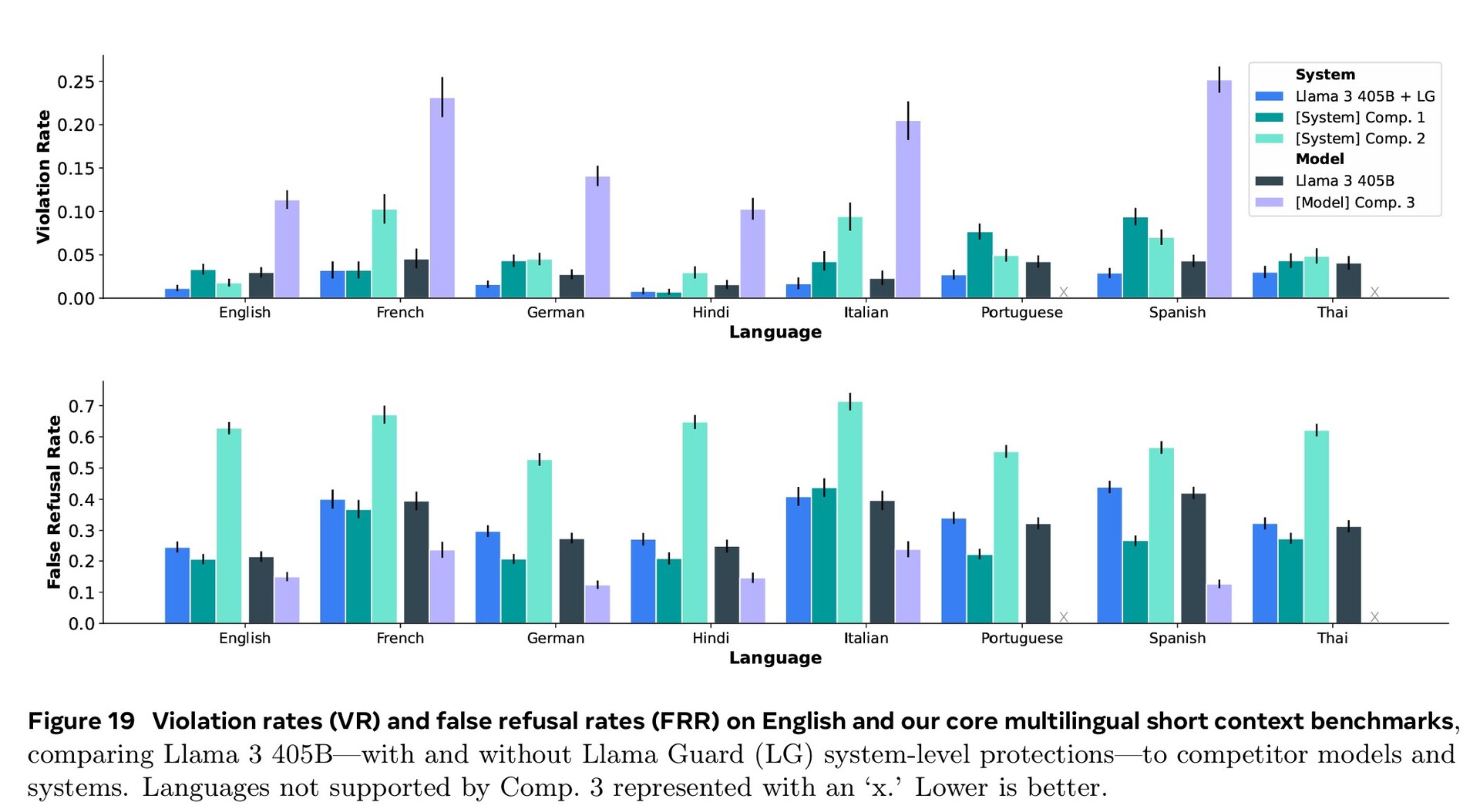
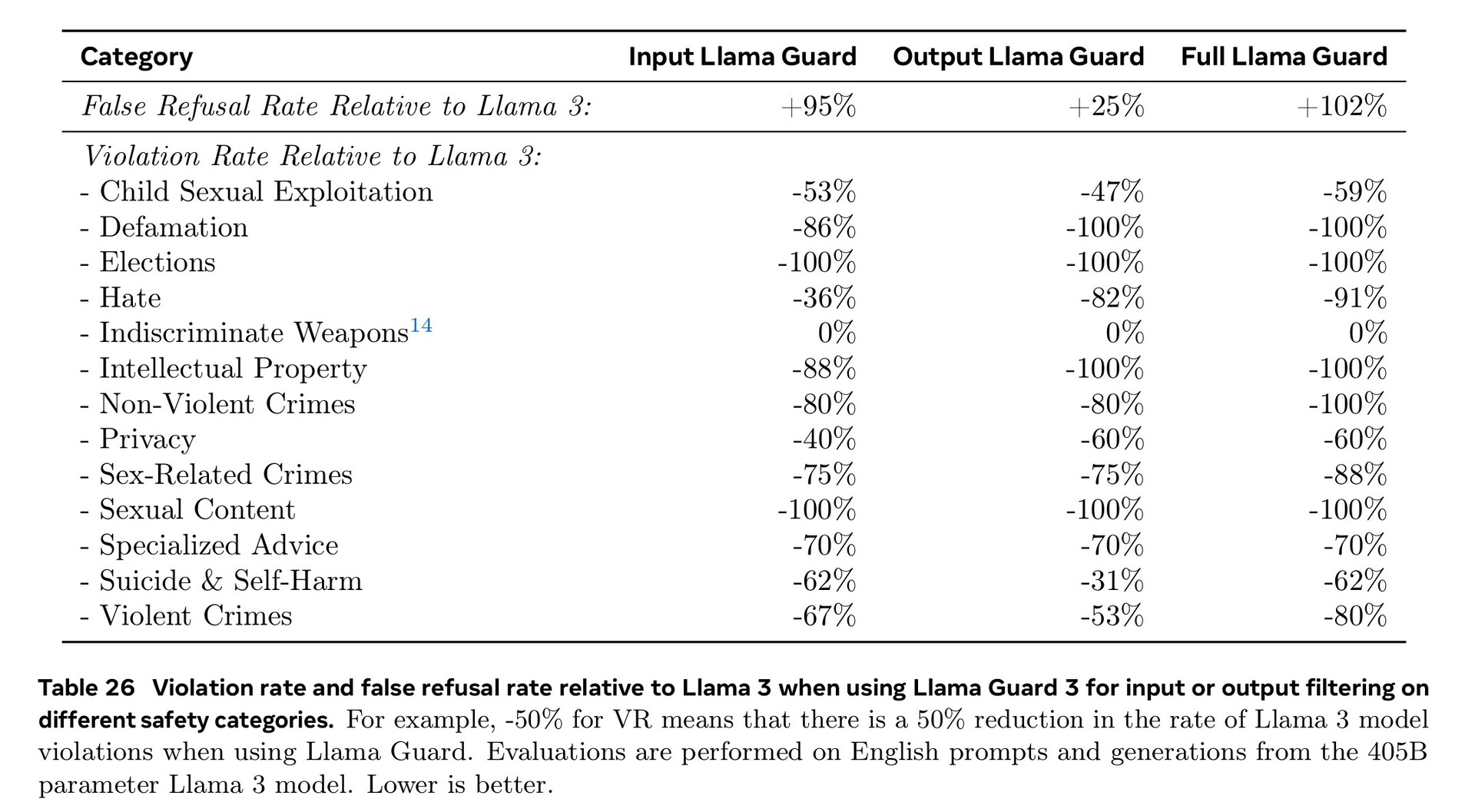
O treinamento extensivo nas áreas de segurança cibernética, segurança infantil, ataque químico e biológico, injeção imediata e muito mais, juntamente com a filtragem de texto de entrada e saída usando o Llama Guard 3, resultou em um desempenho de segurança melhor do que os modelos de IA concorrentes. Ainda assim, a menor quantidade de documentos em idiomas estrangeiros disponíveis para treinamento significa que a Llama 3.1 tem mais probabilidade de responder a perguntas perigosas em português ou francês do que em inglês.
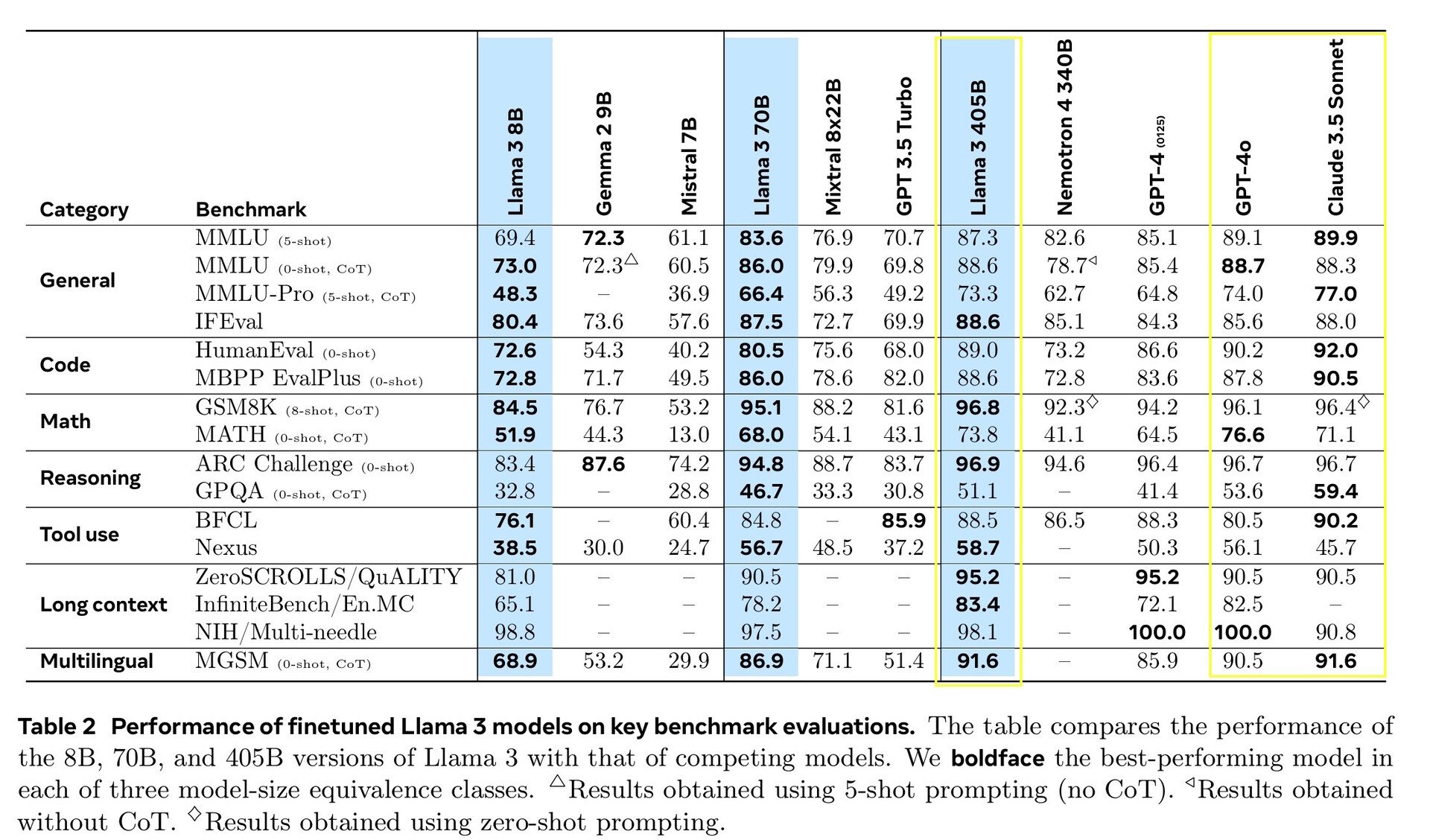
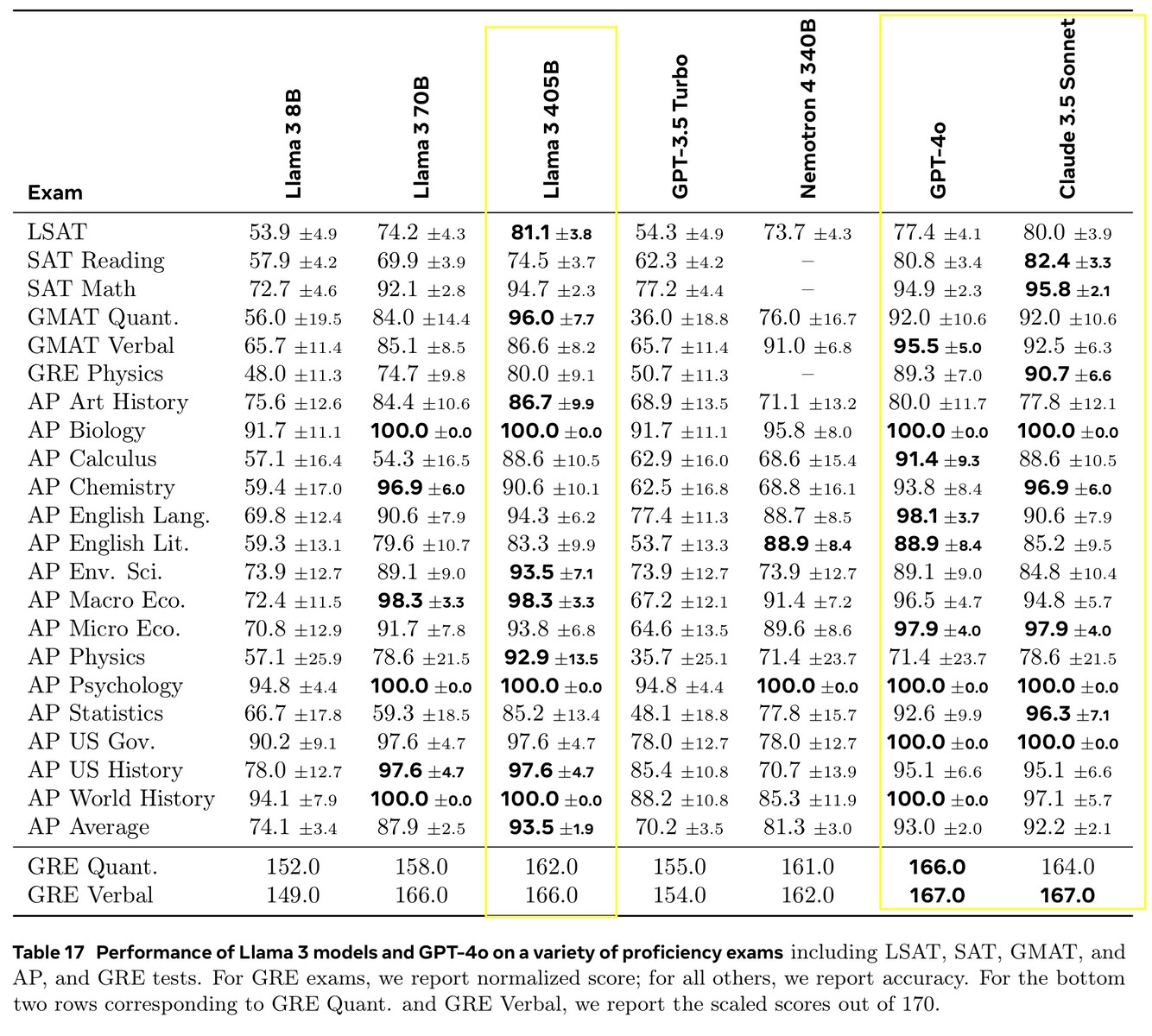
O Llama 3.1 405B obteve uma pontuação de 51,1 a 96,6% em testes de IA de nível universitário e de pós-graduação, em linha com o Claude 3.5 Sonnet e o GPT-4o. Em testes reais avaliados por humanos, o GPT-4o forneceu respostas melhores 52,9% mais frequentemente do que o Llama. O modelo não sabe nada além da data limite de conhecimento de dezembro de 2023, mas pode coletar as informações mais recentes on-line usando Brave Search, resolver problemas de matemática usando Wolfram Alphae resolver problemas de codificação em um interpretador Python https://www.python.org/.
Requisitos
Os pesquisadores interessados em executar o Llama 3.1 405B localmente precisarão de computadores extremamente potentes com 750 GB de espaço de armazenamento livre. Para executar o modelo completo, são necessárias oito GPUs Nvidia A100 ou similar, fornecendo dois nós de MP16 e 810 GB de VRAM de GPU para inferência, em um sistema com 1 TB de RAM. A Meta lançou versões menores que exigem menos, mas têm desempenho pior: Llama 3.1 8B e 70B. O Llama 3.1 8B precisa apenas de 16 GB de VRAM de GPU, portanto, funcionará bem em um sistema bem equipado com Nvidia 4090 bem equipado(como este laptop na Amazon), aproximadamente no nível do GPT-3.5 Turbo. Os leitores que desejam simplesmente usar uma IA de ponta podem instalar um aplicativo como o Anthropic Android ou aplicativo iOS.
Fonte(s)
Modelo de linguagem grande
Apresentamos o Llama 3.1: Nossos modelos mais capazes até o momento
23 de julho de 2024
leitura de 15 minutos
Conclusões:
A Meta está comprometida com a IA de acesso aberto. Leia a carta de Mark Zuckerberg detalhando por que o código aberto é bom para os desenvolvedores, bom para a Meta e bom para o mundo.
Levando a inteligência aberta a todos, nossos modelos mais recentes expandem o comprimento do contexto para 128K, adicionam suporte a oito idiomas e incluem o Llama 3.1 405B, o primeiro modelo de IA de código aberto de nível de fronteira.
O Llama 3.1 405B está em uma classe própria, com flexibilidade e controle incomparáveis e recursos de última geração que rivalizam com os melhores modelos de código fechado. Nosso novo modelo permitirá que a comunidade desbloqueie novos fluxos de trabalho, como a geração de dados sintéticos e a destilação de modelos.
Continuamos a desenvolver o Llama para ser um sistema, fornecendo mais componentes que funcionam com o modelo, incluindo um sistema de referência. Queremos capacitar os desenvolvedores com as ferramentas para criar seus próprios agentes personalizados e novos tipos de comportamentos agênticos. Estamos reforçando isso com novas ferramentas de segurança e proteção, incluindo o Llama Guard 3 e o Prompt Guard, para ajudar a criar com responsabilidade. Também estamos lançando uma solicitação de comentários sobre a Llama Stack API, uma interface padrão que esperamos que facilite a utilização dos modelos da Llama por projetos de terceiros.
O ecossistema está preparado e pronto para funcionar com mais de 25 parceiros, incluindo AWS, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud e Snowflake, que oferecem serviços desde o primeiro dia.
Experimente o Llama 3.1 405B nos EUA no WhatsApp e no meta.ai fazendo uma pergunta desafiadora sobre matemática ou codificação.
LEITURAS RECOMENDADAS
Expandindo o ecossistema da Llama de forma responsável
O ecossistema da Llama: Passado, presente e futuro
Até hoje, os modelos de linguagem de grande porte de código aberto ficaram atrás de seus equivalentes fechados no que diz respeito a recursos e desempenho. Agora, estamos inaugurando uma nova era com o código aberto liderando o caminho. Estamos lançando publicamente o Meta Llama 3.1 405B, que acreditamos ser o maior e mais capaz modelo de base disponível abertamente no mundo. Com um total de mais de 300 milhões de downloads de todas as versões do Llama até o momento, estamos apenas começando.
Apresentando a Llama 3.1
O Llama 3.1 405B é o primeiro modelo disponível abertamente que rivaliza com os principais modelos de IA em termos de recursos de última geração em conhecimento geral, capacidade de direção, matemática, uso de ferramentas e tradução multilíngue. Com o lançamento do modelo 405B, estamos prontos para impulsionar a inovação, com oportunidades sem precedentes de crescimento e exploração. Acreditamos que a última geração do Llama dará início a novos aplicativos e paradigmas de modelagem, incluindo a geração de dados sintéticos para permitir o aprimoramento e o treinamento de modelos menores, bem como a destilação de modelos - um recurso que nunca foi alcançado nessa escala em código aberto.
Como parte desse último lançamento, estamos introduzindo versões atualizadas dos modelos 8B e 70B. Eles são multilíngues e têm um comprimento de contexto significativamente maior de 128K, uso de ferramentas de última geração e recursos de raciocínio mais fortes em geral. Isso permite que nossos modelos mais recentes ofereçam suporte a casos de uso avançados, como resumo de textos longos, agentes de conversação multilíngues e assistentes de codificação. Também fizemos alterações em nossa licença, permitindo que os desenvolvedores usem os resultados dos modelos Llama - incluindo o 405B - para aprimorar outros modelos. Fiel ao nosso compromisso com o código aberto, a partir de hoje, estamos disponibilizando esses modelos para a comunidade para download em llama.meta.com e Hugging Face e para desenvolvimento imediato em nosso amplo ecossistema de plataformas parceiras.
Avaliações de modelos
Para esta versão, avaliamos o desempenho em mais de 150 conjuntos de dados de referência que abrangem uma ampla variedade de idiomas. Além disso, realizamos avaliações humanas abrangentes que comparam a Llama 3.1 com modelos concorrentes em cenários do mundo real. Nossa avaliação experimental sugere que nosso modelo principal é competitivo com os principais modelos de base em uma série de tarefas, incluindo GPT-4, GPT-4o e Claude 3.5 Sonnet. Além disso, nossos modelos menores são competitivos com modelos fechados e abertos que têm um número semelhante de parâmetros.
Arquitetura do modelo
Como nosso maior modelo até agora, o treinamento do Llama 3.1 405B em mais de 15 trilhões de tokens foi um grande desafio. Para permitir execuções de treinamento nessa escala e obter os resultados que obtivemos em um período de tempo razoável, otimizamos significativamente toda a nossa pilha de treinamento e levamos o treinamento do modelo para mais de 16 mil GPUs H100, tornando o 405B o primeiro modelo Llama treinado nessa escala.
Para resolver isso, fizemos escolhas de design que se concentram em manter o processo de desenvolvimento do modelo escalonável e direto.
Optamos por uma arquitetura de modelo de transformador somente de decodificador padrão com pequenas adaptações em vez de um modelo de mistura de especialistas para maximizar a estabilidade do treinamento.
Adotamos um procedimento iterativo de pós-treinamento, em que cada rodada usa ajuste fino supervisionado e otimização direta de preferências. Isso nos permitiu criar dados sintéticos da mais alta qualidade para cada rodada e melhorar o desempenho de cada recurso.
Em comparação com as versões anteriores da Llama, melhoramos a quantidade e a qualidade dos dados que usamos para pré e pós-treinamento. Essas melhorias incluem o desenvolvimento de pipelines de pré-processamento e curadoria mais cuidadosos para dados de pré-treinamento, o desenvolvimento de garantia de qualidade mais rigorosa e abordagens de filtragem para dados de pós-treinamento.
Como esperado pelas leis de escala para modelos de linguagem, nosso novo modelo principal supera os modelos menores treinados usando o mesmo procedimento. Também usamos o modelo de parâmetro 405B para melhorar a qualidade pós-treinamento de nossos modelos menores.
Para dar suporte à inferência de produção em larga escala para um modelo na escala do 405B, quantizamos nossos modelos de numéricos de 16 bits (BF16) para 8 bits (FP8), reduzindo efetivamente os requisitos de computação necessários e permitindo que o modelo seja executado em um único nó de servidor.
Ajuste fino de instruções e bate-papo
Com o Llama 3.1 405B, nos esforçamos para melhorar a utilidade, a qualidade e a capacidade de seguir instruções detalhadas do modelo em resposta às instruções do usuário e, ao mesmo tempo, garantir altos níveis de segurança. Nossos maiores desafios foram o suporte a mais recursos, a janela de contexto de 128K e o aumento do tamanho dos modelos.
No pós-treinamento, produzimos modelos finais de bate-papo fazendo várias rodadas de alinhamento em cima do modelo pré-treinado. Cada rodada envolve Supervised Fine-Tuning (SFT), Rejection Sampling (RS) e Direct Preference Optimization (DPO). Usamos a geração de dados sintéticos para produzir a grande maioria dos nossos exemplos de SFT, iterando várias vezes para produzir dados sintéticos de qualidade cada vez mais alta em todos os recursos. Além disso, investimos em várias técnicas de processamento de dados para filtrar esses dados sintéticos com a mais alta qualidade. Isso nos permite dimensionar a quantidade de dados de ajuste fino em todos os recursos.
Equilibramos cuidadosamente os dados para produzir um modelo com alta qualidade em todos os recursos. Por exemplo, mantemos a qualidade do nosso modelo em benchmarks de contexto curto, mesmo quando estendemos para o contexto de 128K. Da mesma forma, nosso modelo continua a fornecer respostas extremamente úteis, mesmo quando adicionamos atenuações de segurança.
O sistema Llama
Os modelos Llama sempre foram planejados para funcionar como parte de um sistema geral que pode orquestrar vários componentes, incluindo a chamada de ferramentas externas. Nossa visão é ir além dos modelos básicos para dar aos desenvolvedores acesso a um sistema mais amplo que lhes dê flexibilidade para projetar e criar ofertas personalizadas que se alinhem à sua visão. Esse pensamento começou no ano passado, quando introduzimos pela primeira vez a incorporação de componentes fora do núcleo do LLM.
Como parte de nossos esforços contínuos para desenvolver a IA de forma responsável além da camada de modelo e ajudar outras pessoas a fazer o mesmo, estamos lançando um sistema de referência completo que inclui vários aplicativos de amostra e novos componentes, como o Llama Guard 3, um modelo de segurança multilíngue, e o Prompt Guard, um filtro de injeção de prompt. Esses aplicativos de amostra são de código aberto e podem ser desenvolvidos pela comunidade.
A implementação de componentes nessa visão do Sistema Llama ainda é fragmentada. Por isso, começamos a trabalhar com o setor, startups e a comunidade em geral para ajudar a definir melhor as interfaces desses componentes. Para apoiar isso, estamos lançando uma solicitação de comentários no GitHub para o que estamos chamando de "Llama Stack" O Llama Stack é um conjunto de interfaces padronizadas e opinativas sobre como criar componentes canônicos da cadeia de ferramentas (ajuste fino, geração de dados sintéticos) e aplicativos agênticos. Nossa esperança é que elas sejam adotadas em todo o ecossistema, o que deve facilitar a interoperabilidade.
Agradecemos o feedback e as formas de aprimorar a proposta. Estamos entusiasmados com o crescimento do ecossistema em torno da Llama e com a redução das barreiras para desenvolvedores e provedores de plataformas.
A abertura impulsiona a inovação
Ao contrário dos modelos fechados, os pesos dos modelos da Llama estão disponíveis para download. Os desenvolvedores podem personalizar totalmente os modelos de acordo com suas necessidades e aplicativos, treinar em novos conjuntos de dados e realizar ajustes finos adicionais. Isso permite que a comunidade de desenvolvedores mais ampla e o mundo percebam mais plenamente o poder da IA generativa. Os desenvolvedores podem personalizar totalmente seus aplicativos e executá-los em qualquer ambiente, inclusive no local, na nuvem ou até mesmo localmente em um laptop, tudo isso sem compartilhar dados com a Meta.
Embora muitos possam argumentar que os modelos fechados são mais econômicos, os modelos da Llama oferecem um dos menores custos por token do setor, de acordo com testes da Artificial Analysis. E, como observou Mark Zuckerberg, o código aberto garantirá que mais pessoas em todo o mundo tenham acesso aos benefícios e às oportunidades da IA, que o poder não fique concentrado nas mãos de poucos e que a tecnologia possa ser implantada de forma mais uniforme e segura em toda a sociedade. É por isso que continuamos a dar passos no caminho para que a IA de acesso aberto se torne o padrão do setor.
Vimos a comunidade criar coisas incríveis com modelos anteriores da Llama, incluindo um companheiro de estudo de IA criado com a Llama e implementado no WhatsApp e no Messenger, um LLM adaptado para a área médica projetado para ajudar a orientar a tomada de decisões clínicas e uma startup sem fins lucrativos da área de saúde no Brasil que facilita para o sistema de saúde a organização e a comunicação das informações dos pacientes sobre sua hospitalização, tudo de forma segura em termos de dados. Mal podemos esperar para ver o que eles constroem com nossos modelos mais recentes, graças ao poder do código aberto.
Criando com o Llama 3.1 405B
Para o desenvolvedor comum, usar um modelo na escala do 405B é um desafio. Embora seja um modelo incrivelmente potente, reconhecemos que ele exige recursos de computação e experiência significativos para trabalhar com ele. Conversamos com a comunidade e percebemos que há muito mais no desenvolvimento de IA generativa do que apenas modelos de solicitação. Queremos permitir que todos tirem o máximo proveito do 405B, incluindo:
Inferência em tempo real e em lote
Ajuste fino supervisionado
Avaliação do seu modelo para sua aplicação específica
Pré-treinamento contínuo
Geração aumentada por recuperação (RAG)
Chamada de função
Geração de dados sintéticos
É aqui que o ecossistema da Llama pode ajudar. No primeiro dia, os desenvolvedores podem tirar proveito de todos os recursos avançados do modelo 405B e começar a construir imediatamente. Os desenvolvedores também podem explorar fluxos de trabalho avançados, como a geração de dados sintéticos fáceis de usar, seguir instruções prontas para a destilação do modelo e habilitar o RAG contínuo com soluções de parceiros, incluindo AWS, NVIDIA e Databricks. Além disso, a Groq otimizou a inferência de baixa latência para implementações na nuvem, com a Dell obtendo otimizações semelhantes para sistemas locais.
Trabalhamos com os principais projetos da comunidade, como vLLM, TensorRT e PyTorch, para criar suporte desde o primeiro dia e garantir que a comunidade esteja pronta para a implantação na produção.
Esperamos que nosso lançamento do 405B também estimule a inovação em toda a comunidade para facilitar a inferência e o ajuste fino de modelos dessa escala e possibilitar a próxima onda de pesquisa em destilação de modelos.
Experimente a coleção de modelos Llama 3.1 hoje mesmo
Mal podemos esperar para ver o que a comunidade fará com esse trabalho. Há muito potencial para criar novas experiências úteis usando a multilinguagem e o aumento do comprimento do contexto. Com o Llama Stack e as novas ferramentas de segurança, esperamos continuar a construir junto com a comunidade de código aberto de forma responsável. Antes de lançar um modelo, trabalhamos para identificar, avaliar e atenuar os possíveis riscos por meio de várias medidas, incluindo exercícios de descoberta de riscos antes da implantação por meio de equipes vermelhas e ajuste fino de segurança. Por exemplo, realizamos um extenso trabalho de equipe vermelha com especialistas externos e internos para testar os modelos e descobrir maneiras inesperadas de usá-los. (Leia mais sobre como estamos dimensionando nossa coleção de modelos Llama 3.1 de forma responsável neste post do blog)
Embora este seja o nosso maior modelo até o momento, acreditamos que ainda há muito terreno novo a ser explorado no futuro, incluindo tamanhos mais compatíveis com dispositivos, modalidades adicionais e mais investimentos na camada de plataforma do agente.
Este trabalho contou com o apoio de nossos parceiros em toda a comunidade de IA. Gostaríamos de agradecer e reconhecer (em ordem alfabética): Accenture, Amazon Web Services, AMD, Anyscale, CloudFlare, Databricks, Dell, Deloitte, Fireworks.ai, Google Cloud, Groq, Hugging Face, IBM WatsonX, Infosys, Intel, Kaggle, Microsoft Azure, NVIDIA, OctoAI, Oracle Cloud, PwC, Replicate, Sarvam AI, Scale.AI, SNCF, Snowflake, Together AI e o projeto vLLM desenvolvido no Sky Computing Lab da UC Berkeley.








