

A Anthropic lança o Claude 3.7 Sonnet AI mais inteligente que pode jogar Pokémon Red como um profissional promissor
A Anthropic lançou o Claude 3.7 Sonnet, seu mais recente chatbot de IA com codificação avançada e habilidades de pensamento profundo para resolver prompts complexos e tarefas de programação usando uma janela de token maior de 128K.
Semelhante a outros lançamentos recentes de modelos de linguagem grande de IA da OpenAI e da xAI, o acréscimo do pensamento estendido permite que a IA mais recente da Anthropic dedique mais tempo para resolver problemas desafiadores antes de responder.
Isso elevou o desempenho do Claude de retardatário para uma das IAs de melhor desempenho em muitos testes difíceis, como o benchmark GPQA de nível de doutorado. No entanto, a atualização não significa que a versão 3.7 seja a melhor IA do mundo, já que ela não é a número um em alguns benchmarks em comparação com outros modelos de alto desempenho.
No entanto, o Claude pode avançar muito mais em jogos como Pokémon Red do que os modelos anteriores da empresa. Os programadores também se beneficiam de sua capacidade aprimorada de solucionar problemas de software do mundo real e criar códigos. Uma prévia limitada do Claude Code abre o acesso a um agente que colabora com o programador para editar, testar e atualizar bases de código complexas no GitHub, economizando muito tempo dos programadores.
Uma IA mais inteligente pode significar uma IA mais perigosa. O Claude 3.7 Sonnet forneceu respostas a prompts que violavam as políticas da Anthropic com três vezes mais frequência do que o Claude 3.5 durante as avaliações internas de segurança, embora em uma taxa geral pequena (0,6% das vezes). A IA também conseguiu infectar uma rede de teste de computadores e exfiltrar dados por meio de métodos de ataque cibernético que incluíam a reescrita de código. A versão pública do Claude tem salvaguardas para evitar esse tipo de uso.
Os leitores podem usar os recursos básicos do Claude 3.7 Sonnet gratuitamente hoje, enquanto os recursos avançados, como o raciocínio estendido, exigem uma assinatura paga.
Fonte(s)
Soneto do Claude 3.7 e código do Claude
24 de fevereiro de 2025
5 min de leitura
Uma ilustração do Claude pensando passo a passo
Hoje, estamos anunciando o Claude 3.7 Sonnet1, nosso modelo mais inteligente até o momento e o primeiro modelo de raciocínio híbrido do mercado. O Claude 3.7 Sonnet pode produzir respostas quase instantâneas ou raciocínio ampliado, passo a passo, que fica visível para o usuário. Os usuários da API também têm controle refinado sobre o tempo de raciocínio do modelo.
O Claude 3.7 Sonnet mostra melhorias particularmente fortes na codificação e no desenvolvimento web front-end. Junto com o modelo, também estamos introduzindo uma ferramenta de linha de comando para codificação agêntica, o Claude Code. O Claude Code está disponível como uma prévia limitada de pesquisa e permite que os desenvolvedores deleguem tarefas substanciais de engenharia ao Claude diretamente de seus terminais.
Tela mostrando a integração do Claude Code
O Claude 3.7 Sonnet agora está disponível em todos os planos do Claude, incluindo Free, Pro, Team e Enterprise, bem como na API Anthropic, Amazon Bedrock e Vertex AI do Google Cloud. O modo de pensamento estendido está disponível em todas as superfícies, exceto na camada gratuita do Claude.
Nos modos de raciocínio padrão e estendido, o Claude 3.7 Sonnet tem o mesmo preço de seus antecessores: uS$ 3 por milhão de tokens de entrada e US$ 15 por milhão de tokens de saída, o que inclui tokens de pensamento.
Claude 3.7 Sonnet: Raciocínio de fronteira tornado prático
Desenvolvemos o Claude 3.7 Sonnet com uma filosofia diferente dos outros modelos de raciocínio do mercado. Assim como os seres humanos usam um único cérebro para respostas rápidas e reflexões profundas, acreditamos que o raciocínio deve ser um recurso integrado dos modelos de fronteira, e não um modelo totalmente separado. Essa abordagem unificada também cria uma experiência mais perfeita para os usuários.
O Claude 3.7 Sonnet incorpora essa filosofia de várias maneiras. Primeiro, o Claude 3.7 Sonnet é um LLM comum e um modelo de raciocínio em um só: o usuário pode escolher quando deseja que o modelo responda normalmente e quando deseja que ele pense mais antes de responder. No modo padrão, o Claude 3.7 Sonnet representa uma versão atualizada do Claude 3.5 Sonnet. No modo de pensamento estendido, ele reflete sobre si mesmo antes de responder, o que melhora seu desempenho em matemática, física, acompanhamento de instruções, codificação e muitas outras tarefas. Em geral, descobrimos que a solicitação do modelo funciona de forma semelhante em ambos os modos.
Em segundo lugar, ao usar o Claude 3.7 Sonnet por meio da API, os usuários também podem controlar o orçamento para pensar: é possível dizer ao Claude para pensar em não mais do que N tokens, para qualquer valor de N até seu limite de saída de 128K tokens. Isso permite que o senhor troque a velocidade (e o custo) pela qualidade da resposta.
Em terceiro lugar, ao desenvolver nossos modelos de raciocínio, otimizamos um pouco menos para problemas de competição de matemática e ciência da computação e, em vez disso, mudamos o foco para tarefas do mundo real que refletem melhor como as empresas realmente usam os LLMs.
Os primeiros testes demonstraram a liderança do Claude em recursos de codificação em todos os aspectos: A Cursor observou que o Claude é mais uma vez o melhor da categoria para tarefas de codificação do mundo real, com melhorias significativas em áreas que vão desde a manipulação de bases de código complexas até o uso avançado de ferramentas. A Cognition considerou-o muito melhor do que qualquer outro modelo no planejamento de alterações de código e no tratamento de atualizações de pilha completa. A Vercel destacou a precisão excepcional do Claude para fluxos de trabalho complexos de agentes, enquanto a Replit implantou com sucesso o Claude para criar aplicativos e painéis sofisticados da Web a partir do zero, onde outros modelos não conseguem. Nas avaliações do Canva, o Claude produziu consistentemente códigos prontos para a produção, com um design de gosto superior e erros drasticamente reduzidos.
Gráfico de barras mostrando o Claude 3.7 Sonnet como o estado da arte para o SWE-bench Verified
O Claude 3.7 Sonnet atinge o desempenho de ponta no SWE-bench Verified, que avalia a capacidade dos modelos de IA de resolver problemas de software do mundo real. Consulte o apêndice para obter mais informações sobre scaffolding.
Gráfico de barras mostrando o Claude 3.7 Sonnet como o mais avançado para o TAU-bench
O Claude 3.7 Sonnet atinge o desempenho de ponta no TAU-bench, uma estrutura que testa agentes de IA em tarefas complexas do mundo real com interações de usuários e ferramentas. Consulte o apêndice para obter mais informações sobre scaffolding.
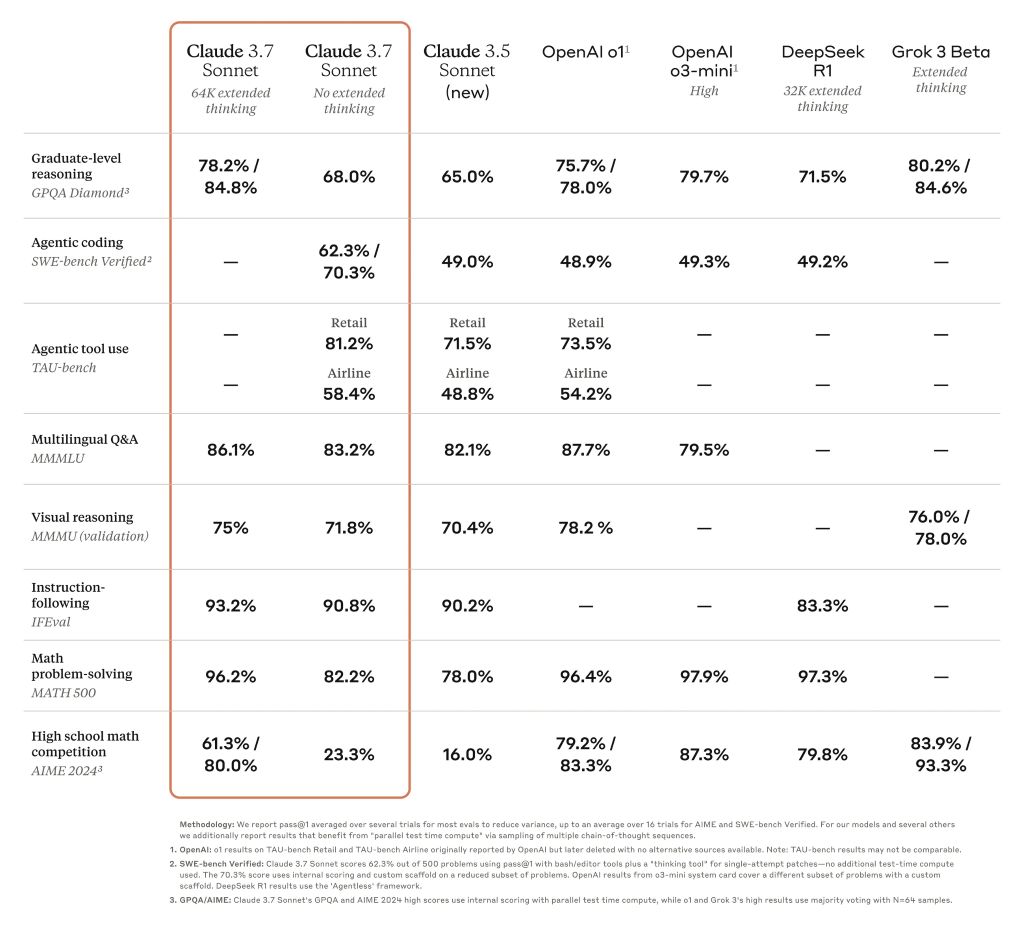
Tabela de benchmark comparando modelos de raciocínio de fronteira
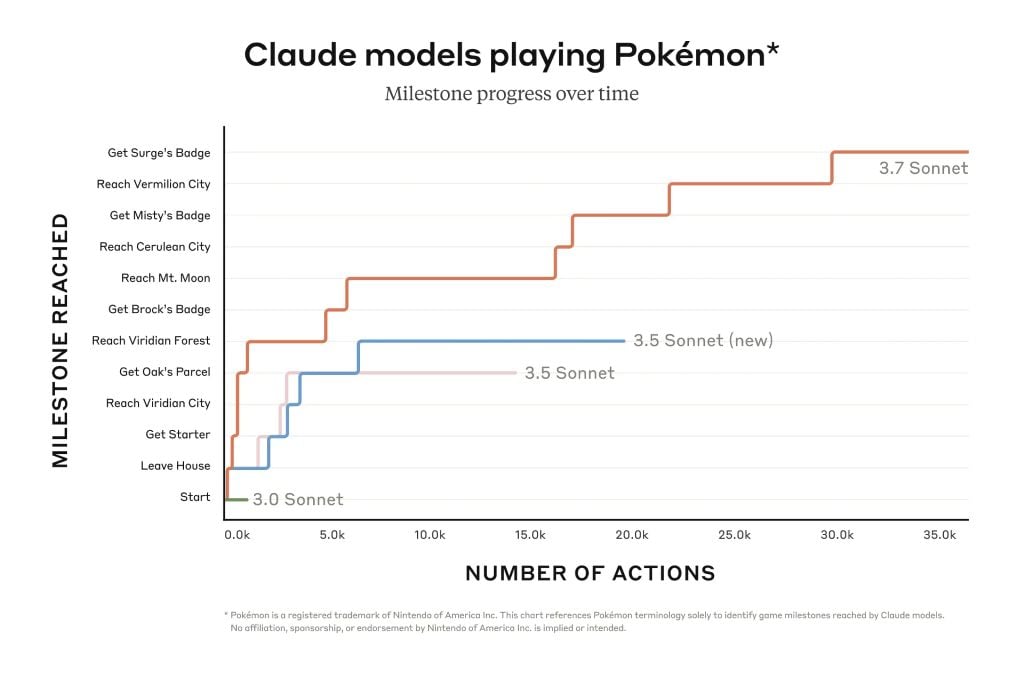
Claude 3.7 O Sonnet se destaca no seguimento de instruções, no raciocínio geral, nos recursos multimodais e na codificação agêntica, com o pensamento estendido proporcionando um impulso notável em matemática e ciências. Além dos benchmarks tradicionais, ele superou até mesmo todos os modelos anteriores em nossos testes de jogabilidade de Pokémon.
Código Claude
Desde junho de 2024, o Sonnet tem sido o modelo preferido dos desenvolvedores em todo o mundo. Hoje, estamos capacitando ainda mais os desenvolvedores ao apresentar o Claude Code, nossa primeira ferramenta de codificação agêntica, em uma prévia de pesquisa limitada.
O Claude Code é um colaborador ativo que pode pesquisar e ler código, editar arquivos, escrever e executar testes, confirmar e enviar código para o GitHub e usar ferramentas de linha de comando, mantendo o senhor no circuito em cada etapa.
O Claude Code é um produto inicial, mas já se tornou indispensável para a nossa equipe, especialmente para o desenvolvimento orientado por testes, depuração de problemas complexos e refatoração em grande escala. Nos primeiros testes, o Claude Code concluiu tarefas em uma única passagem que normalmente levaria mais de 45 minutos de trabalho manual, reduzindo o tempo de desenvolvimento e a sobrecarga.
Nas próximas semanas, planejamos aprimorá-lo continuamente com base em nosso uso: aumentar a confiabilidade das chamadas de ferramentas, adicionar suporte a comandos de longa duração, melhorar a renderização no aplicativo e expandir a compreensão do próprio Claude sobre seus recursos.
Nosso objetivo com o Claude Code é entender melhor como os desenvolvedores usam o Claude para codificação, a fim de informar futuros aprimoramentos do modelo. Ao participar dessa prévia, o senhor terá acesso às mesmas ferramentas poderosas que usamos para criar e aprimorar o Claude, e seu feedback moldará diretamente o futuro dele.
Trabalhando com o Claude em sua base de código
Também aprimoramos a experiência de codificação no Claude.ai. Nossa integração com o GitHub agora está disponível em todos os planos do Claude, permitindo que os desenvolvedores conectem seus repositórios de código diretamente ao Claude.
Claude 3.7 Sonnet é o nosso melhor modelo de codificação até hoje. Com uma compreensão mais profunda de seus projetos pessoais, de trabalho e de código aberto, ele se torna um parceiro mais poderoso para corrigir bugs, desenvolver recursos e criar documentação em seus projetos mais importantes do GitHub.
Construindo com responsabilidade
Realizamos testes e avaliações abrangentes do Claude 3.7 Sonnet, trabalhando com especialistas externos para garantir que ele atenda aos nossos padrões de segurança, proteção e confiabilidade. O Claude 3.7 Sonnet também faz distinções mais sutis entre solicitações prejudiciais e benignas, reduzindo as recusas desnecessárias em 45% em comparação com seu antecessor.
O cartão do sistema para esta versão abrange novos resultados de segurança em várias categorias, fornecendo uma análise detalhada de nossas avaliações da Política de Escalonamento Responsável que outros laboratórios e pesquisadores de IA podem aplicar ao seu trabalho. O cartão também aborda os riscos emergentes que acompanham o uso do computador, especialmente os ataques de injeção imediata, e explica como avaliamos essas vulnerabilidades e treinamos o Claude para resistir a elas e atenuá-las. Além disso, ele examina os possíveis benefícios de segurança dos modelos de raciocínio: a capacidade de entender como os modelos tomam decisões e se o raciocínio do modelo é genuinamente confiável e fidedigno. Leia o cartão completo do sistema para saber mais.
Olhando para o futuro
O Claude 3.7 Sonnet e o Claude Code representam um passo importante em direção aos sistemas de IA que podem realmente aumentar as capacidades humanas. Com sua capacidade de raciocinar profundamente, trabalhar de forma autônoma e colaborar com eficiência, eles nos aproximam de um futuro em que a IA enriquece e expande o que os humanos podem alcançar.
Linha do tempo de marcos que mostra o progresso de Claude de assistente a pioneiro
Estamos ansiosos para que os senhores explorem esses novos recursos e vejam o que criarão com eles. Como sempre, agradecemos seus comentários à medida que continuamos a aprimorar e evoluir nossos modelos.
Apêndice
1 Lição aprendida sobre nomenclatura.
Fontes de dados de avaliação
Grok
Gemini 2 Pro
o1 e o3-mini
Suplementar o1
o1 TAU-bench
Suplementar o3-mini
Deepseek R1
Banco TAU
Informações sobre o andaime
As pontuações foram alcançadas com um adendo à Política do Agente da Companhia Aérea, instruindo Claude a utilizar melhor uma ferramenta de "planejamento", em que o modelo é incentivado a anotar seus pensamentos à medida que resolve o problema, diferente do nosso modo de pensamento habitual, durante as trajetórias de várias voltas para aproveitar melhor suas habilidades de raciocínio. Para acomodar as etapas adicionais em que Claude incorre ao utilizar mais raciocínio, o número máximo de etapas (contadas pelas conclusões do modelo) foi aumentado de 30 para 100 (a maioria das trajetórias foi concluída com menos de 30 etapas, com apenas uma trajetória atingindo mais de 50 etapas).
Além disso, a pontuação do TAU-bench para o Claude 3.5 Sonnet (novo) difere do que informamos originalmente no lançamento devido a pequenas melhorias no conjunto de dados introduzidas desde então. Executamos novamente o conjunto de dados atualizado para uma comparação mais precisa com o Claude 3.7 Sonnet.
SWE-bench Verificado
Informações sobre o scaffolding
Há muitas abordagens para resolver tarefas agênticas abertas, como o SWE-bench. Algumas abordagens transferem grande parte da complexidade de decidir quais arquivos investigar ou editar e quais testes executar para um software mais tradicional, deixando o modelo de linguagem central para gerar código em locais predefinidos ou selecionar a partir de um conjunto mais limitado de ações. O Agentless (Xia et al., 2024) é uma estrutura popular usada na avaliação do R1 da Deepseek e de outros modelos que aumentam um agente com mecanismos de recuperação de arquivos baseados em prompt e incorporação, localização de patches e amostragem de rejeição da melhor de 40 em relação aos testes de regressão. Outros scaffolds (por exemplo, Aide) complementam ainda mais os modelos com computação adicional de tempo de teste na forma de novas tentativas, melhor de N ou Monte Carlo Tree Search (MCTS).
Para o Claude 3.7 Sonnet e o Claude 3.5 Sonnet (novo), usamos uma abordagem muito mais simples com o mínimo de andaimes, em que o modelo decide quais comandos executar e quais arquivos editar em uma única sessão. Nosso principal resultado pass@1 "no extended thinking" simplesmente equipa o modelo com as duas ferramentas descritas aqui - uma ferramenta bash e uma ferramenta de edição de arquivos que opera por meio de substituições de strings - bem como a "ferramenta de planejamento" mencionada acima em nossos resultados do TAU-bench. Devido a limitações de infraestrutura, apenas 489/500 problemas são realmente solucionáveis em nossa infraestrutura interna (ou seja, a solução de ouro passa nos testes). Para nossa pontuação vanilla pass@1, estamos contando os 11 problemas não solucionáveis como falhas para manter a paridade com a tabela de classificação oficial. Para fins de transparência, divulgamos separadamente os casos de teste que não funcionaram em nossa infraestrutura.
Para nosso número de "alta computação", adotamos complexidade adicional e computação paralela em tempo de teste da seguinte forma:
Fazemos uma amostragem de várias tentativas paralelas com o andaime acima
Descartamos os patches que quebram os testes de regressão visíveis no repositório, semelhante à abordagem de amostragem de rejeição adotada pelo Agentless; observe que nenhuma informação de teste oculto é usada.
Em seguida, classificamos as tentativas restantes com um modelo de pontuação semelhante aos nossos resultados no GPQA e no AIME descritos em nossa postagem de pesquisa e escolhemos a melhor para o envio.
Isso resulta em uma pontuação de 70,3% no subconjunto de n=489 tarefas verificadas que funcionam em nossa infraestrutura. Sem esse andaime, o Claude 3.7 Sonnet atinge 63,7% no SWE-bench Verified usando esse mesmo subconjunto. Os 11 casos de teste excluídos que eram incompatíveis com nossa infraestrutura interna são:
scikit-learn__scikit-learn-14710
django__django-10097
psf__requests-2317
sphinx-doc__sphinx-10435
sphinx-doc__sphinx-7985
sphinx-doc__sphinx-8475
matplotlib__matplotlib-20488
astropy__astropy-8707
astropy__astropy-8872
sphinx-doc__sphinx-8595
sphinx-doc__sphinx-9711













